



















A knowledge base is the right choice for many AI use cases. Internal FAQ bots, customer support assistants, and onboarding chatbots run reliably on well-maintained knowledge bases today. Retrieval-augmented generation over indexed documents is a proven pattern for stable, single-domain knowledge, and LinkedIn’s coding assistant reduced issue triage time by 70% using exactly this approach. If your agents answer questions from stable documentation, a knowledge base will serve you well. The question this page answers is a narrower one: what are the specific thresholds where a knowledge base becomes the wrong architecture, and what does an agent context layer provide that a knowledge base fundamentally cannot? According to McKinsey, only 6% of surveyed companies report significant value capture from AI investments. The gap is not in the models. It is in the context those models receive.
When a knowledge base is sufficient
Permalink to “When a knowledge base is sufficient”Knowledge bases earn their place in the AI stack. Before explaining where they fall short, it is worth being precise about where they genuinely work.
Internal wikis for narrow-domain Q&A. When a single team owns all the relevant content, updates happen quarterly or less, and wrong answers are annoying but not expensive, a vector-indexed document set handles the job. One team, stable content, low ambiguity: this is the ideal knowledge base scenario.
Static documentation for onboarding chatbots. New employee onboarding assistants work well with knowledge bases because the underlying policies, team structures, and process docs are updated infrequently. The risk of a stale answer is low, and the surface area is bounded.
FAQ retrieval for customer support. High query volume, low complexity, well-defined question patterns: knowledge bases excel here. This pattern works reliably at scale and does not require cross-system identity resolution or governance enforcement.
Coding assistant context. Language documentation, API references, internal style guides, and framework conventions are exactly the kind of stable, single-domain reference material that knowledge bases handle well. LinkedIn’s CAPT framework achieved a 70% reduction in issue triage time using a coding knowledge base, with no context layer required.
Single-domain RAG where data does not cross systems. If an agent’s entire knowledge surface lives in one system with one consistent vocabulary and no governance requirements, RAG accuracy problems are manageable with good chunking and retrieval strategies. The context layer becomes necessary when the agent needs to cross system boundaries.
The common thread across all of these: the knowledge is stable, lives in one place, has one unambiguous meaning, and the cost of occasional stale answers is acceptable. When any of those conditions breaks down, the architecture needs to evolve.
Agent context layer vs knowledge base: a full comparison
Permalink to “Agent context layer vs knowledge base: a full comparison”| Dimension | Knowledge Base | Context Layer |
|---|---|---|
| Data model | Static documents (PDFs, wikis, FAQs, markdown). Text chunks with vector embeddings. Relationships inferred from chunk proximity. | Living metadata graph. Entities (tables, metrics, people, policies) are nodes; relationships (ownership, lineage, certification, access) are edges. Continuously updated. |
| Update mechanism | Manual edit workflows. Someone updates the document, triggers re-indexing, new embeddings become available. Estimated 80% of enterprise knowledge bases are out of date at any given time. | Active sync from source systems. When a table is deprecated in Snowflake, the context layer updates. When a glossary term is recertified, agents receive the new definition on next query. No manual re-index cycle. |
| Provenance tracking | Document-level only. The agent knows “this answer came from Document X.” Cannot trace which transformation pipeline produced the underlying data, who certified it, or whether Document X is still authoritative. | Asset-level and transformation-level. Tracks: which data asset answered the question, which transformation pipeline produced it, who owns it, which version, certification status, quality score, when last updated, and full column-level lineage. |
| Governance support | Human-managed access controls. Document-level ACLs and role-based access. Static: permissions set at ingestion time, do not respond dynamically to query context or runtime policy evaluation. | Programmatic policy enforcement at inference time. Access, action, data, temporal, and contextual policies combine at runtime. The context layer defines what can be retrieved, how trust is assigned, and how memory boundaries are enforced. |
| Multi-agent support | Each agent queries independently. No shared substrate for coordination. Two agents can return inconsistent answers to the same question because there is no shared context state. | Shared substrate for coordinated agents. A single source of contextual truth (business definitions, lineage, policies) that all agents query the same way. Context updates propagate to all agents simultaneously. |
| Cross-system identity resolution | Documents are siloed. Confluence has one document about “ARR,” Salesforce has another, the data warehouse has a third. The agent surfaces them as separate retrieval results without resolving that they describe the same metric differently. | Resolves entity identity across systems. Maps canonical definitions to physical assets across 400+ data sources. “Revenue” in the context layer is one certified, versioned concept, not three conflicting document chunks. |
| Freshness guarantee | Fresh only when manually updated. Freshness degrades at the pace of organizational change versus KB maintenance velocity. Enterprise KB platforms cannot automatically detect downstream data asset changes and propagate them to KB documents. | Continuously synced from source systems. When a table is deprecated, when a glossary term is updated, when an asset fails a quality check, the context layer propagates changes before the next agent query. |
| Explainability | Shows which document was retrieved. Sufficient for citation in low-stakes Q&A. Insufficient for audit-grade AI in regulated industries where explainability must trace to source data and transformations. | Full decision trace: which data asset, which transformation, which owner, which version, which policy applied at inference time. Supports the explainability levels required by the EU AI Act’s transparency provisions (effective August 2026). |
| Query interface | Natural language to vector similarity search to top-k document chunks. Works for “what does our policy say about X.” Fails when questions require multi-hop reasoning, entity disambiguation, governance-aware filtering, or real-time state. | Natural language to structured graph query, semantic search, and policy evaluation. Returns certified business definitions, lineage paths, quality signals, usage patterns, and policy constraints assembled dynamically for the specific task. |
| Ideal deployment scenario | Internal FAQ bots, customer support Q&A, documentation search, onboarding chatbots, coding assistants, single-domain agents with stable low-complexity knowledge. | Cross-functional analytics agents, multi-agent orchestration, regulated industry deployments, revenue analysis, financial reporting agents, agents that take actions rather than just answering questions. |
| Failure mode | Returns stale, contradictory, or imprecise answers when documentation has not been maintained, when multiple documents cover the same topic with conflicting definitions, or when questions require cross-system reasoning. | Can become a bottleneck if the graph is not actively maintained or if metadata quality degrades. The failure mode is structural (wrong schema, wrong relationships) rather than staleness-based. |
Static vs. dynamic: the core architectural difference
Permalink to “Static vs. dynamic: the core architectural difference”The most important distinction between a knowledge base and a context layer is not a feature list. It is a fundamentally different relationship between the AI system and the organization’s knowledge over time.
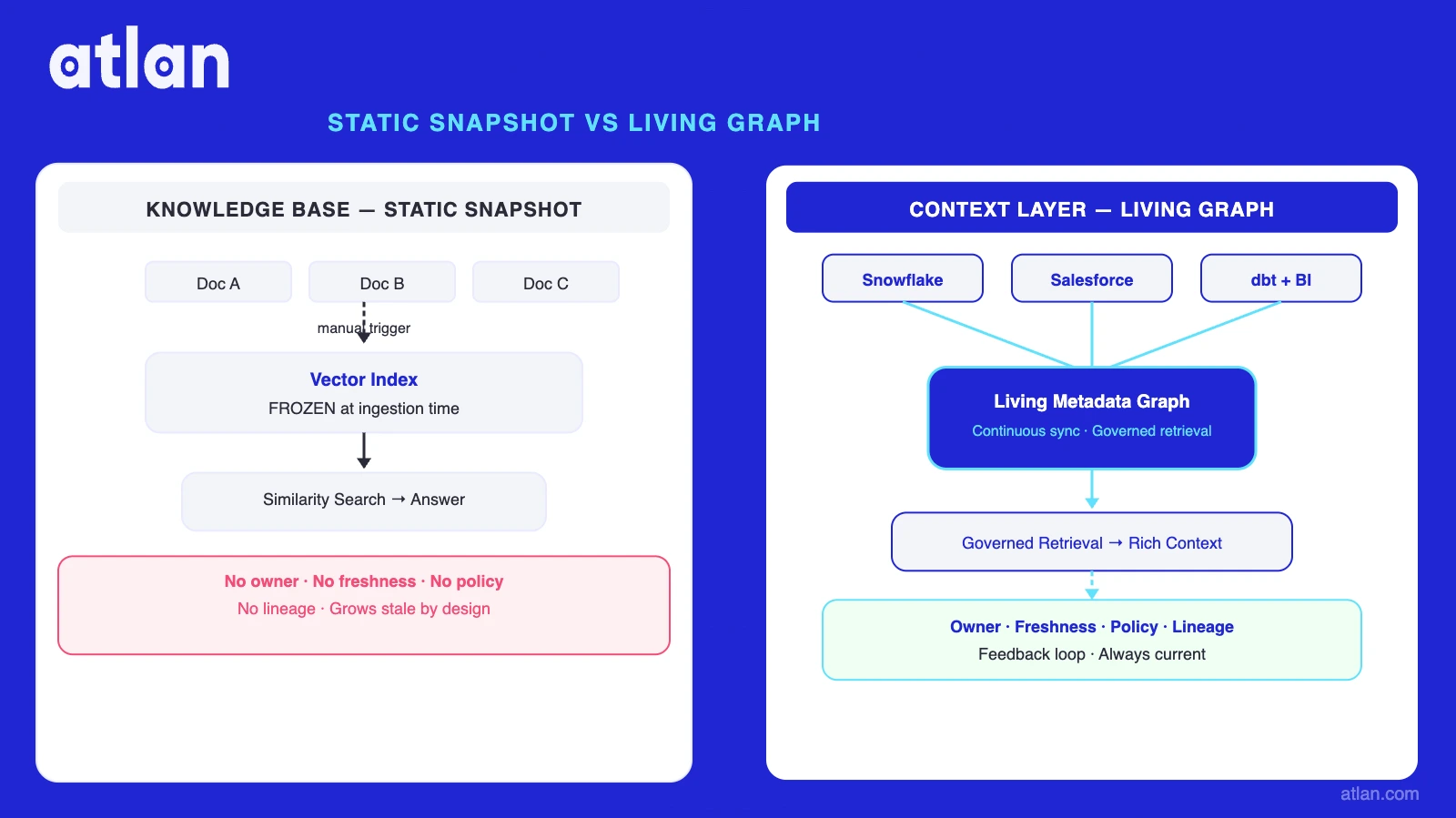
KNOWLEDGE BASE ARCHITECTURE
────────────────────────────────────────────────────
[Doc 1] [Doc 2] [Doc 3] [Doc 4]
|
Ingestion pipeline <-- manual trigger
|
[Vector Index] <-- frozen at ingestion time
|
Similarity search
|
Top-k chunks returned
|
Agent answer
(no owner · no freshness · no policy · no lineage)
Last updated: depends on when a human updated it
Feedback loop: none
────────────────────────────────────────────────────
In this architecture, the knowledge base is a snapshot. It reflects the state of the organization’s documentation at the moment it was last indexed. Every passing day introduces potential staleness. When the agent answers a question, it retrieves text. It does not know whether that text is still authoritative, whether it contradicts something in another document, or whether the data it describes has changed since the document was written.
CONTEXT LAYER ARCHITECTURE
────────────────────────────────────────────────────
[Snowflake] [Salesforce] [dbt] [BI Tools]
| active connectors, continuous sync
|
[Living Metadata Graph]
Nodes: tables, metrics, people, policies, glossary
Edges: ownership, lineage, certification, access
|
[Active Ontology] + [Governance Policies]
|
Governed query via MCP
|
Context retrieval:
- Certification status: verified
- Data owner: @finance-team
- Lineage: Snowflake > dbt > certified view
- Freshness: 2 hours ago
- Policy: Finance-Analyst role required
|
Agent answer + provenance trace + policy enforcement
|
[Production corrections feed back into the graph] <--
────────────────────────────────────────────────────
The context layer is a living system. When a table is deprecated, the graph updates. When a business glossary term is recertified, all agents receive the updated definition. When an agent produces an output and a human corrects it, that correction can propagate back. The feedback loop is the structural difference: a knowledge base grows stale by design; a context layer stays current by design.
A knowledge base answers: what does our documentation say. A context layer answers: what does our data mean, where did it come from, is it still trusted, and who can see it.
For context architecture, the living graph is what makes agents trustworthy at enterprise scale. Atlan’s research shows 82.5% RAG precision with metadata enrichment, compared to 73.3% without.
The use case matrix: which fits your deployment?
Permalink to “The use case matrix: which fits your deployment?”| Governance: None to Minimal | Governance: Enterprise (HIPAA, SOX, GDPR) | |
|---|---|---|
| Data Complexity: Low | Knowledge base sufficient. Internal FAQ bots, onboarding assistants, customer support Q&A, coding assistants. Knowledge is stable, lives in one place, has one unambiguous meaning. LinkedIn CAPT is a strong example. Wrong answers are annoying, not expensive. | Knowledge base with access controls may work. HR policy bots, legal research assistants, compliance Q&A for a single business unit. Document-level ACLs handle the access requirement when policy is relatively static. Breaks when entitlements change frequently or when the agent must reason about its own answer’s sensitivity before responding. |
| Data Complexity: High | Context layer for semantic clarity. Cross-functional analytics agents, multi-department revenue analysis, data mesh environments where multiple teams own the same metric differently. A knowledge base surfaces conflicting definitions; a context layer resolves which one applies in this query context. The Workday revenue analysis agent is the canonical example. | Context layer required. Regulated industry AI agents, financial reporting agents, healthcare data assistants, agents that execute actions. Both axes demand it: complex data means cross-system identity resolution is necessary; enterprise governance means policy enforcement at inference time is non-negotiable. A knowledge base cannot enforce data residency rules dynamically, apply row-level access controls based on role and query context, or provide an audit trail that satisfies regulatory scrutiny. |

The quadrant most teams underestimate is the lower-left: high complexity, minimal formal governance. These are the teams where agents start returning inconsistent answers across business units, not because of a governance failure but because “revenue” in Finance means something different from “revenue” in Sales. A knowledge base surfaces both definitions. A unified context layer resolves them.
Gartner reports that 63% of organizations have significant gaps in knowledge base readiness for agentic AI. The readiness gap is not primarily technical; it is semantic and organizational. Context engineering is the discipline that closes it. For a deeper look at the context engineering vs prompt engineering distinction, that page covers how the two disciplines interact.
When your knowledge base becomes a bottleneck
Permalink to “When your knowledge base becomes a bottleneck”These six signals mean your knowledge base has reached its structural limits. Each maps to a specific capability that only a context layer provides.
Signal 1: Agents give inconsistent answers across business units. “Churn” in Customer Success means something different from “churn” in Finance. The knowledge base picks whichever document chunk has higher vector similarity. Context layer fix: a governed business glossary with certified, authoritative definitions. All agents query the same canonical definition, mapped to every downstream table and BI report.
Signal 2: Compliance teams request data provenance after an AI-generated report. The compliance officer asks which tables produced the number, who approved the transformation, and what the certification status of the upstream asset is. The knowledge base can only say “this came from Document X.” Context layer fix: column-level lineage and decision traces. Full traceability: which asset, which transformation, which owner, which version, at what time.
Signal 3: Knowledge base content contradicts itself. The wiki has a 2024 revenue methodology document, a 2025 update, and a Confluence page that was never retired. The agent synthesizes a contradictory answer, or confidently returns the outdated version because it had higher semantic similarity. Context layer fix: certification status and version control at the asset level. Agents only query certified assets unless explicitly directed otherwise.
Signal 4: Multi-agent workflows return conflicting context. Agent A processed a financial report using Monday’s definition of “active users.” Agent B processed the same report using an updated definition from later that day. The consolidated output is internally inconsistent. Context layer fix: a shared context substrate via MCP. All agents query the same context layer through the same interface. Context updates propagate to all agents simultaneously.
Signal 5: The knowledge base requires continuous manual maintenance to stay useful. The team spends more time updating the KB than building new agents. Every schema change, every business logic update, every new data source requires a document update and re-indexing. Context layer fix: active metadata and automated context assembly. Atlan’s Context Engineering Studio generates 90% of context from existing assets automatically. When a table is added to the warehouse, the context layer classifies it and makes it available to agents without a manual KB update.
Signal 6: Agents are moving from answering questions to taking actions. The stakes shift from “user is slightly confused” to “wrong data was written to production.” A knowledge base was not designed for runtime authorization. Context layer fix: policy-enforced context with runtime authorization. The context layer enforces who can do what with which data under which conditions. An agent attempting to write to a certified dataset under a data quality hold is blocked, not just warned.
The upgrade path: from knowledge base to context layer
Permalink to “The upgrade path: from knowledge base to context layer”A context layer does not replace a knowledge base. It sits above one, extending the architecture with the layers that knowledge bases cannot provide: governed identity, active sync, policy enforcement, and cross-system lineage.
The upgrade path matters because most teams that need a context layer already have knowledge bases. They have Confluence, Notion, or a vector database with indexed documentation. They have governance documents, data dictionaries, and business glossaries in some form. The problem is that none of this is AI-readable in a way that supports context-aware AI agents operating across systems.
Atlan’s Context Engineering Studio reads existing knowledge artifacts and bootstraps context automatically. Business glossary terms from Confluence map to physical assets in Snowflake. Governance policies from existing documentation become runtime-enforceable access controls. The team’s existing governance investment, which took years to build, becomes AI-readable through Atlan’s MCP server in weeks rather than months.
What changes when you add a context layer: agents receive governed, freshness-tagged, policy-enforced answers rather than raw similarity rankings. The metadata layer for AI becomes a living infrastructure rather than a static index. The Atlan context layer and enterprise AI memory page covers how this powers persistent, governed agent memory at scale.
What stays the same: the knowledge base still stores documents. The context layer does not replace document retrieval for cases where document retrieval is appropriate. For bounded, stable, single-domain queries, the knowledge base continues to serve its purpose. The context layer handles the cross-system, multi-agent, governed use cases alongside it.
For teams exploring the enterprise context layer architecture, the transition is additive. You are not discarding the work done on knowledge bases. You are building the layer that makes that work interoperable with the rest of the data stack.
The context engineering framework describes how these layers combine: document retrieval sits at the bottom, enriched by structured metadata, governed by a context layer that enforces policy and tracks provenance across the full stack. Each layer handles what it is designed for. For a survey of the tools available, see agent context layer tools and the full agent context layer tools compared analysis.
If you are evaluating how a context layer differs from other retrieval architectures, agent context layer vs RAG covers that distinction in depth. For the question of whether your enterprise specifically needs one, do enterprises need a context layer provides a decision framework.
Why Workday needed more than a knowledge base
Permalink to “Why Workday needed more than a knowledge base”Joe DosSantos, VP Enterprise Data and Analytics at Workday, described the moment clearly. Workday built a revenue analysis agent as part of their AI infrastructure initiative. The agent had access to data: tables, schemas, documents, the full technical surface. It could retrieve documents. It could run queries. And it could not answer one question about revenue.
“We built a revenue analysis agent and it couldn’t answer one question. We started to realize we were missing this translation layer. We had no way to interpret human language against the structure of the data.”
The problem was not retrieval. The knowledge base approach had given the agent text about revenue definitions. But the agent could not map those text definitions to specific columns in the data warehouse. It could not determine which version of the definition was currently certified. It could not apply the access controls that determined which revenue figures were appropriate for which users. It could not resolve “revenue” across CRM, ERP, and warehouse where the same metric appeared with different names and different grain.
This is the context drift detection problem in a concrete form. The agent had context. The context was fragmented, inconsistent, and ungrounded in the physical data structure.
What solved it was not a better knowledge base. Workday leveraged the shared language they had already built across the organization: business definitions, semantic relationships, domain governance. The fix was turning existing governance investment into AI-consumable context, exposed through Atlan’s MCP server as runtime-queryable endpoints.
“All of the work that we did to get to a shared language amongst people at Workday can be leveraged by AI via Atlan’s MCP server. We can start to teach AI language.”
The result: a 5x improvement in AI response accuracy for the revenue analysis agent. The model did not change. The data did not change. The context infrastructure changed.
This is the Workday insight that matters for this comparison: this is not a story about a knowledge base failing. It is a story about the threshold. Workday had done the knowledge work. They had business definitions, governance processes, and shared language. The problem was that none of it was AI-readable in a way that grounded agents in the physical structure of the data. The context layer is not a replacement for the knowledge work. It is the infrastructure that makes existing knowledge work available to agents.
Atlan’s research corroborates this at scale: a 38% SQL accuracy improvement across 522 enterprise queries when agents are grounded in context-rich metadata rather than semantic definitions alone (p-value less than 0.0001). The business context for AI is the variable that most consistently improves accuracy. Adding a structured ontology layer (a component of a context layer) produces a 20% improvement in agent answer accuracy and a 39% reduction in unnecessary tool calls, per Snowflake’s internal research.
For teams building multi-agent system orchestration, the shared context substrate is not optional. It is the coordination mechanism. Without it, agents operating on the same data return inconsistent results, and the AI agent observability surface becomes unmanageable. The memory layer vs context layer distinction matters here: memory handles what happened in a session; the context layer handles what data means across all sessions and all agents. For the AI governance framework perspective on why this distinction matters at enterprise scale, that page covers the full governance architecture.
Frequently asked questions
Permalink to “Frequently asked questions”1. Can a knowledge base and a context layer coexist?
Permalink to “1. Can a knowledge base and a context layer coexist?”Yes, and this is the most common architecture in practice. The context layer does not replace document retrieval for cases where document retrieval is appropriate. For bounded, stable, single-domain queries, the knowledge base continues to serve its purpose. The context layer handles cross-system, multi-agent, and governed use cases alongside it. Atlan’s Context Engineering Studio reads existing knowledge base artifacts as inputs during bootstrapping, preserving the value of existing documentation work.
2. When does a knowledge base become a compliance risk?
Permalink to “2. When does a knowledge base become a compliance risk?”When AI agents begin producing outputs that inform regulated decisions (financial reporting, healthcare data, HR decisions) and those outputs cannot be traced to source data with certification status and access controls. Document-level citation from a knowledge base does not satisfy the explainability requirements of EU AI Act Article 13 for high-risk AI systems (taking effect August 2026). If compliance teams are asking “where did this number come from and who approved it,” a knowledge base cannot fully answer that question. See AI agent risks and guardrails for the full compliance picture.
3. Does switching to a context layer mean rebuilding everything?
Permalink to “3. Does switching to a context layer mean rebuilding everything?”No. The context layer is an additive architecture. Existing knowledge bases, data dictionaries, governance documents, and business glossaries are inputs to the context layer, not things it replaces. Atlan’s Context Engineering Studio bootstraps 90% of context from an existing data estate. One insurance customer compressed a projected one-year context layer build to one month using this approach. For a practical starting point, see agent context layer design.
4. What is the difference between a context layer and a knowledge graph?
Permalink to “4. What is the difference between a context layer and a knowledge graph?”A knowledge graph encodes factual relationships between concepts. A context graph encodes operational relationships between data assets: ownership, lineage, certification, access policy, and organizational meaning. A context layer is the infrastructure that makes the context graph available to AI agents at runtime, with governance enforcement built in. The distinction is between a map of facts and a living operational system.
5. How do knowledge bases fail in multi-agent systems?
Permalink to “5. How do knowledge bases fail in multi-agent systems?”Each agent queries the knowledge base independently. There is no shared substrate for coordination. One agent can act on Monday’s definition while another acts on Tuesday’s updated definition, producing inconsistent outputs. The types of AI agent memory framework distinguishes per-agent memory from shared context: a knowledge base is effectively per-agent memory that happens to be shared by coincidence, not by design. A context layer is explicitly designed for shared context across agents, with updates propagating simultaneously. For the full picture, see common context problems data teams hit.
6. What is the role of MCP in connecting agents to a context layer?
Permalink to “6. What is the role of MCP in connecting agents to a context layer?”The Model Context Protocol is the open standard that lets any MCP-compatible agent query a context layer through a consistent interface. Atlan’s MCP server exposes four endpoint types: semantic search, lineage traversal, policy checks, and update operations. This means Claude, ChatGPT, Gemini, Cursor, and Copilot Studio all receive the same governed, freshness-tagged, policy-enforced context without custom integration work for each agent framework. The context catalog describes how these endpoints surface the full context for agents. For the full what is context engineering picture, that page covers how MCP fits into the broader context engineering discipline.
Sources
Permalink to “Sources”- McKinsey State of AI 2025: 72% of organizations use GenAI; 6% report significant value capture. McKinsey and Company, 2025.
- Gartner: 63% of organizations report significant gaps in knowledge base readiness for AI agents. Gartner, 2026.
- Knowmax: 80% of enterprise knowledge bases are out of date. Knowmax, 2026.
- Atlan internal research: 38% SQL accuracy improvement across 522 enterprise queries with context-rich metadata vs. semantic definitions alone (p-value less than 0.0001). Atlan, 2026.
- Atlan internal research: 82.5% RAG precision with metadata enrichment vs. 73.3% without. Atlan, based on Atlan LLM knowledge base data.
- Snowflake Engineering: 20% improvement in agent answer accuracy and 39% reduction in tool calls when an ontology layer is added. Cited via Atlan published content.
- Workday: 5x improvement in AI analyst response accuracy after grounding agents in shared context via Atlan. Atlan published customer content, 2026.
- LinkedIn CAPT: 70% reduction in issue triage time with a coding knowledge base. The New Stack, February 2026.
- Galileo: Multi-agent coordination failures and context loss as a root cause. Galileo AI, Why Multi-Agent Systems Fail, 2026.
- EU AI Act, Article 13 transparency provisions for high-risk AI systems, effective August 2026.
- AI Governance Statistics 2026: Only 12% of organizations describe their AI governance as mature. Prefactor, 2026.
- ResearchGate: AI-enhanced provenance tracking achieves 92% accuracy vs. 68% for manual approaches. ResearchGate, Data Lineage and Provenance Using AI in Enterprise Governance, 2026.
- The New Stack: Six agentic knowledge base patterns emerging in the wild, including shared business context layers for ERP and financial agents. The New Stack, February 2026.
- InfoWorld: Anatomy of an AI agent knowledge base, freshness as the number one challenge. InfoWorld, 2026.
- Elixirdata: Decision traces vs. logs for AI audit trail compliance. Elixirdata, 2026.
