



















Most teams treat agent context layer design as a retrieval problem: choose a vector database, tune chunking, ship. The evidence says the accuracy lever sits one level earlier. Atlan AI Labs tested 522 enterprise queries and found a 38% SQL accuracy improvement when agents were grounded in governance metadata: certified definitions, lineage, and sensitivity classification, rather than raw schema alone. The design decisions you make before implementation begins determine whether that lift is available to every agent on your platform or none of them.
What is agent context layer design?
Permalink to “What is agent context layer design?”Agent context layer design is the set of architectural decisions made before implementation begins. It answers three questions: how the context layer will be shared across agents, how governance rules will be encoded into it, and how it will stay portable as the data stack evolves. Implementation guides tell you how to build; design principles tell you what to build toward.
| Quick Facts | |
|---|---|
| What it covers | Shared substrate design, governance encoding, portability, lifecycle policy, cross-platform coverage |
| Who it matters to | Data architects, AI platform leads, data engineers building their first or second agent |
| When it applies | Before tooling selection, before implementation begins |
| What it prevents | Per-agent context sprawl, platform lock-in, stale context, definition drift in multi-agent systems |
| Primary evidence | 38% SQL accuracy lift from governance enrichment (Atlan AI Labs, p < 0.0001, n=522 queries) |
The five design principles that separate production context layers from POC projects
Permalink to “The five design principles that separate production context layers from POC projects”Every architecture decision in the sections below maps back to one of these five principles. Violate one and you build a context layer that serves the current agent. Apply all five and you build context as infrastructure that serves every agent your organization will ever deploy.
Principle 1: Portability over lock-in
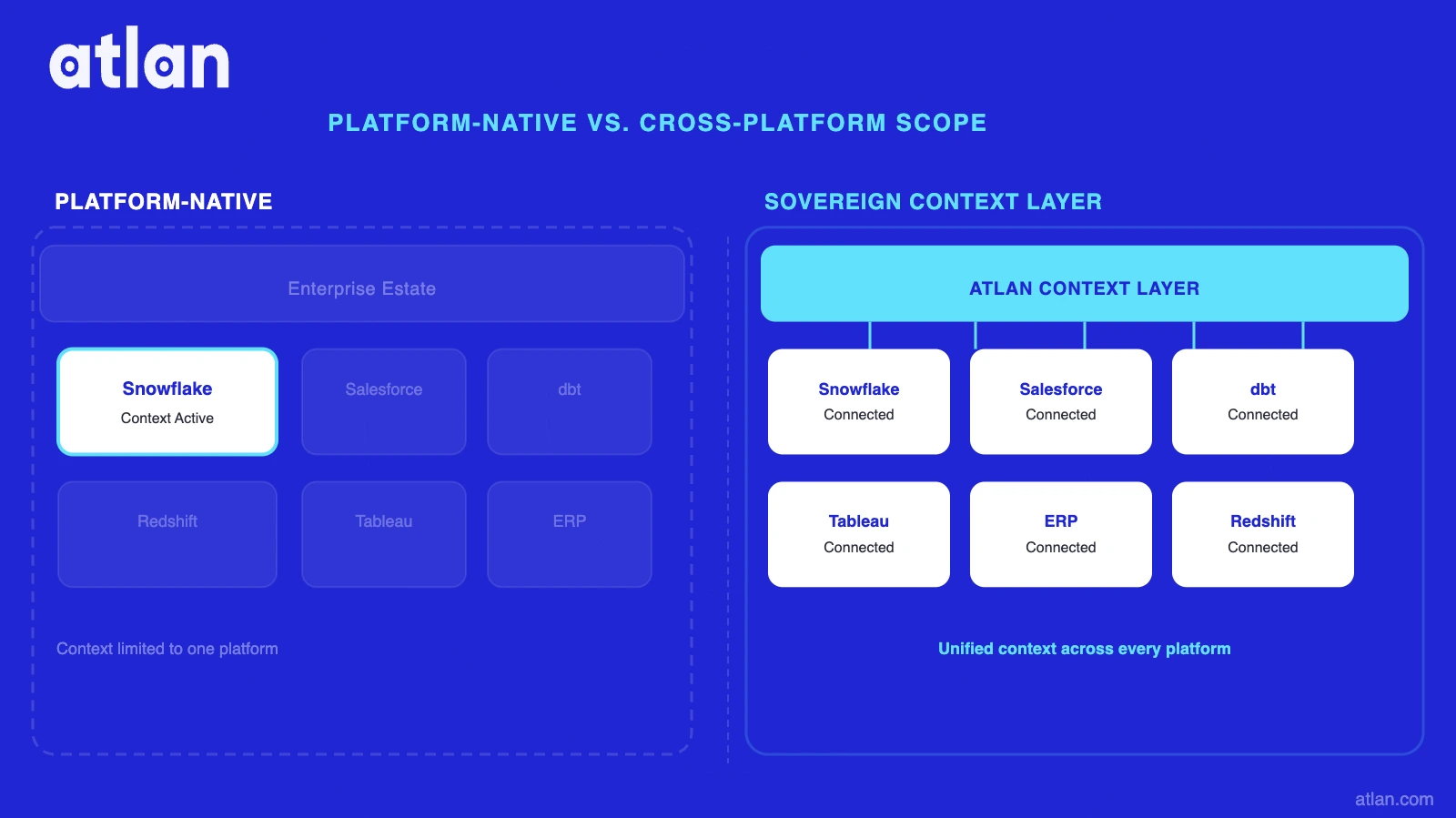
Design the context architecture above any single data platform. Enterprise data estates span 40 to 100+ systems: warehouses, BI, SaaS, ERP, CRM. A context layer built inside one platform’s boundary covers only a fraction of the enterprise data graph. A unified context layer is built on open protocols and open APIs so it survives vendor transitions without a full rebuild.
Principle 2: Governance before retrieval
Encode business rules, certified definitions, and access policies into the context layer at build time, not retrieval time. Retrieval optimization (better vectors, smarter chunking) does not substitute for governance enrichment. The 38% SQL accuracy lift from Atlan AI Labs came from governance metadata, not a retrieval change. Medium-complexity queries showed a 2.15x improvement, which is where retrieval alone fails most.
Principle 3: Shared substrate over per-agent context
The five core components of a context layer (business glossary, lineage, policies, ownership, and classifications) should be built once and shared across every agent, copilot, and AI tool in the organization. When context is built per agent, a definition change requires N updates. When context is infrastructure, it requires one. This is the context engineering framework principle: context is direction, not per-agent configuration.
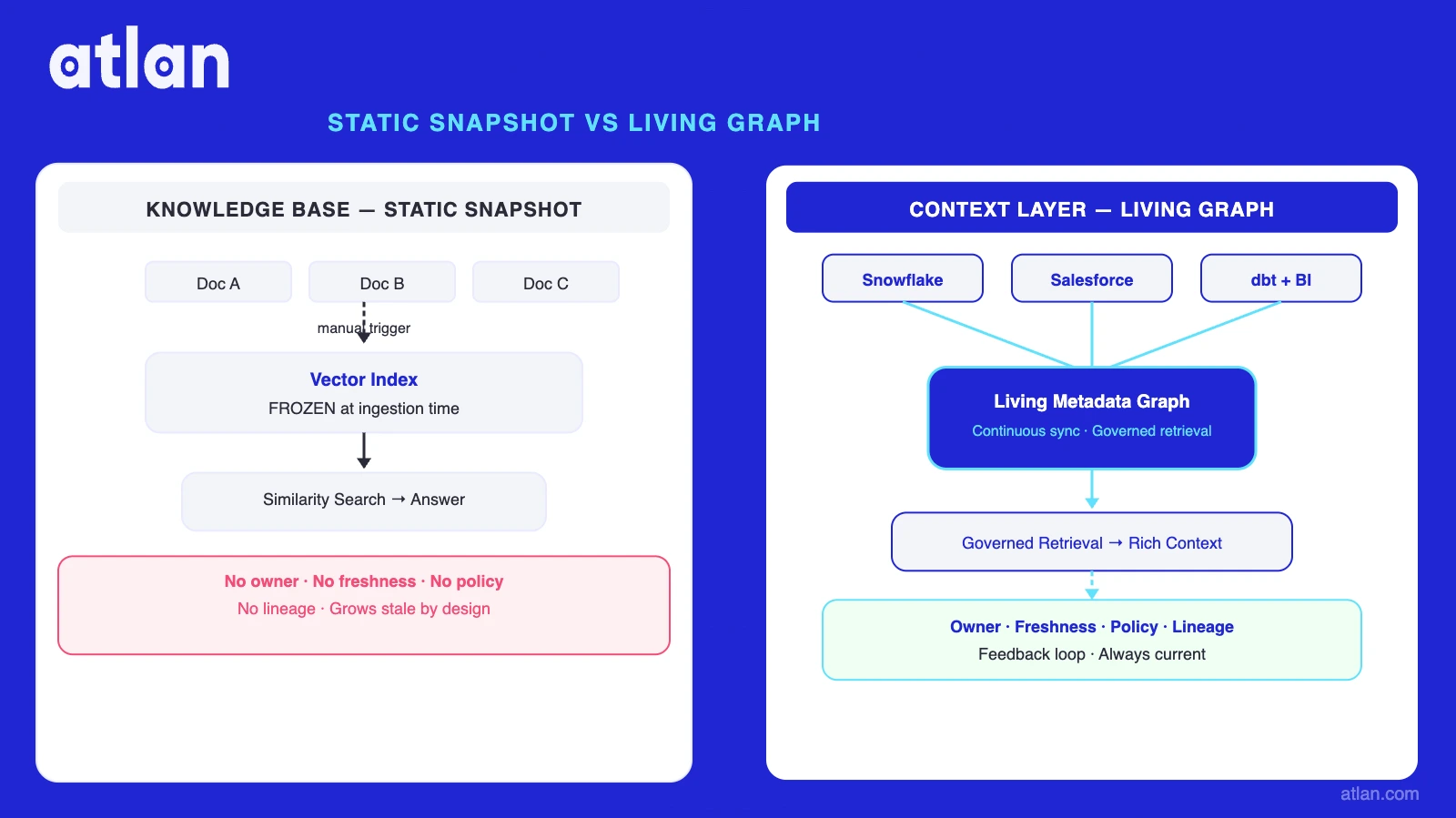
Principle 4: Actively governed, not static snapshot
A context layer designed as a one-time documentation effort will fail in production. Schemas change. Ownership changes. Certifications expire. Active context engineering means updates propagate through the layer continuously, with defined ownership, review cadences, and propagation rules. Stale context produces confident wrong answers with no exception thrown.
Principle 5: Minimal sufficiency over volume
More context is not better context. Atlan AI Labs found that an optimized 64-line metadata format outperforms a verbose 176-line format by 13.8% at half the cost. Context layer output should be scoped, structured, and itemized so agents select precisely rather than parse everything.
Design decision framework
Permalink to “Design decision framework”Before picking a tool, five architectural decisions need to be made. Each maps to a specific set of requirements. The difference between context engineering vs. prompt engineering is largely about making these decisions explicit rather than letting them default to whatever the first tool chosen happens to support.
| Design Dimension | Platform-native approach | Cross-platform approach | When to use platform-native | When to use cross-platform |
|---|---|---|---|---|
| Scope | Context inside a single data warehouse or lakehouse (e.g., Snowflake Cortex, Databricks Unity Catalog) | Context layer sitting above the data stack, spanning 5+ systems | Team consolidated on one platform; single-platform agent use cases only | Enterprise has multiple data systems; agents need cross-system answers spanning warehouse, CRM, and ERP |
| Protocol | Proprietary API or framework-native context injection | Open standard (MCP) exposing context to any agent framework; see MCP vs. proprietary API | Single agent framework; framework-native integration is sufficient | Multiple agent frameworks in use or planned; avoid re-integration per tool |
| Governance model | Context built once as an initial documentation effort, minimal ongoing maintenance | Context updated continuously as definitions, ownership, and schemas change | Purely experimental pilots; no compliance requirements | Regulated industries; governance is a requirement; agents act on sensitive data |
| Context representation | Vector database with semantic similarity retrieval | Knowledge graph with entity relationships, ontology, and structured lineage; see context layer vs. semantic layer | Pure document retrieval; RAG over static documents | Agents need to resolve entities across systems, trace lineage, or enforce policies |
| Ownership model | Central data team owns all context definitions | Federated: domain teams own domain context, central team sets standards; see who owns the context layer | Small org; one team has full data breadth | Data mesh or domain-oriented org; scale requires distributed ownership |
One decision cuts across all five dimensions: Gartner (May 2026) predicts 60% of agentic analytics projects relying solely on MCP without a governed substrate underneath will fail by 2028. MCP is a protocol, not a context layer. What sits behind the MCP server determines outcome quality.
Anti-patterns: what teams get wrong when building context layers
Permalink to “Anti-patterns: what teams get wrong when building context layers”The following anti-patterns are documented from enterprise implementations, practitioner research, and Atlan AI Labs observations. The common context problems data teams hit at scale all trace back to one or more of these design failures.
| Anti-pattern | What it looks like | Why it fails | Fix |
|---|---|---|---|
| Building context per agent instead of shared | Each agent gets its own RAG pipeline, prompt library, or schema documentation. Three agents, three context sources. | A definition change must be updated in three places. Different agents answer the same business question differently. | Design the context layer as shared infrastructure from the first agent. One source of truth, consumed by all. |
| Using a knowledge base when governance is required | Confluence, Notion, or SharePoint used as the context substrate. See: context layer vs. knowledge base. | Knowledge bases handle document retrieval, not access control, certification status, temporal validity, or definition conflicts. Agents produce document-accurate but business-incorrect answers. | Design the context substrate to include governance metadata: certified definitions, ownership, sensitivity classification, and policy enforcement. |
| Treating RAG as a context layer | RAG pipeline is built, UAT passes, and the team considers context done. See: context layer vs. RAG. | RAG retrieves relevant text; it does not encode governance rules, lineage, or certification state. RAG accuracy limitations widen on complex queries and governance edge cases. | Layer governance metadata and business glossary on top of retrieval. Context layer design precedes RAG tuning. |
| Platform-native lock-in | Context layer built inside a single data warehouse. Works on single-platform queries. | Most enterprise questions cross system boundaries: revenue (warehouse) joined with customer segments (CRM) and contract status (ERP). Platform-native context cannot answer cross-system questions or enforce cross-system governance. | Design the context layer above the data stack as a sovereign layer, not inside any single platform. |
| Skipping provenance and lineage at design time | Teams document what metrics mean but not where they came from, how they were derived, or which decisions they governed. | In regulated industries this is a compliance failure. In any enterprise, agents produce answers that cannot be audited. Gartner (May 2026): prioritize vendors that support decision-trace data capture at the infrastructure level. | Design lineage and decision tracing as first-class requirements before picking a context platform. |
| No lifecycle policy | Context is built once and never updated. Definitions, ownership, and schemas change without propagating into the context layer. | Stale context produces confident wrong answers with no exception thrown. Context drift is the most cited enterprise AI failure mode after initial deployment. Agent accuracy degrades over time even without model changes. | Define ownership, review cadence, and update propagation rules as part of design. Lifecycle policy is a design decision. |
| Context volume over context quality | Teams over-document to cover all edge cases. Verbose catalogs replace scoped, structured output. | Atlan AI Labs: a 64-line optimized format outperforms a 176-line verbose format by 13.8%. Unstructured context dilutes signal. | Design context with structured, scoped, itemized output. Each element should be tagged by asset, ownership, certification status, and retrieval signal. |
| Multi-agent context isolation | Each agent in a multi-agent system maintains isolated context state drawn from a different snapshot. | Agents disagree on definitions during cross-agent handoffs. Confusion between memory layer vs. context layer compounds the problem: memory is per-agent and ephemeral; context should be shared and persistent. | Design for shared context from the first architectural decision. All agents read from the same governed substrate. |
Architecture decision checklist
Permalink to “Architecture decision checklist”Before determining whether your enterprise needs a context layer and before selecting any tooling, use these 14 criteria at the whiteboard. They cover the decisions that determine long-term viability, not just initial deployment success. For multi-agent context management, items 6 and 7 are the most frequently skipped.
-
Cross-platform coverage: How many data systems does the context layer span? Does it cover the warehouse, BI layer, SaaS, ERP, and CRM? Platform-native solutions cover one system boundary by design.
-
MCP support: Does the platform expose context via Model Context Protocol so any MCP-compatible agent framework can consume it without custom integration per tool?
-
Lineage depth: Does the platform capture column-level lineage, not just table-level? Can an agent trace the full derivation path for a specific metric back to its source?
-
Governance controls: Are access policies enforced at query time, not just documented? Does the platform propagate guardrails and risk controls to agents at runtime?
-
Freshness and update policy: How does the context layer detect and propagate schema changes, ownership changes, and definition updates? What is the maximum tolerable lag?
-
Multi-agent support: Can multiple agents share the same context substrate without isolation issues? Does the platform handle concurrent reads with consistency guarantees across agent frameworks?
-
Auditability and decision tracing: Does the platform capture which context elements governed each agent decision? Can the organization reconstruct the reasoning path for observability and auditability requirements?
-
Versioning: Are context definitions versioned? Can teams roll back to a prior definition if an update causes regressions?
-
Bootstrap path: Does the platform offer AI-assisted bootstrapping from existing SQL history, BI semantics, and lineage, or does it require manual documentation from scratch?
-
Evaluation capability: Can teams test context quality before production deployment? Does the platform generate evaluation suites from existing queries and dashboards?
-
Ownership and stewardship model: Does the platform support both federated ownership and centralized models, or does it force one approach?
-
Provenance enforcement: Is provenance metadata required for every context element and enforced at ingestion, or is it optional and therefore inconsistent?
-
Cost and token efficiency: Does the platform optimize context output for token efficiency, or does it return raw data dumps that inflate inference costs?
-
Open standards commitment: Is the platform built on open protocols and open APIs? What is the migration path if the organization needs to switch platforms in 18 months?
When evaluating agent context layer tools or looking to compare agent context layer tools, these 14 criteria map directly to the product capabilities that separate context infrastructure from context configuration.
How Atlan approaches context layer design
Permalink to “How Atlan approaches context layer design”The five design principles above are not theoretical. They reflect what high-performing enterprise context layers have in common, and Atlan’s architecture is built around all five.
When Workday built a revenue analysis agent, it failed not because the model was weak but because the translation layer was missing. Joe DosSantos, VP Enterprise Data and Analytics at Workday, described the problem: “We built a revenue analysis agent and it couldn’t answer one question. We started to realize we were missing this translation layer. We had no way to interpret human language against the structure of the data.” Atlan’s MCP server provided the shared business language that connects natural language to governed data operations. DosSantos: “All of the work that we did to get to a shared language amongst people at Workday can be leveraged by AI via Atlan’s MCP server. We can start to teach AI language.”
The accuracy evidence is reproducible. Atlan AI Labs ran 522 enterprise queries with and without governance-enriched context. The result: 38% relative improvement in AI-generated SQL accuracy (p < 0.0001). Medium-complexity queries showed a 2.15x improvement, with an ROI of 2,662% at $4.02 per 1,000 queries. Snowflake independently validated the finding: adding an organizational ontology to agents produced a 20% improvement in agent accuracy and a 39% reduction in tool calls.
Atlan’s Context Engineering Studio operationalizes the shared substrate principle by reading the Enterprise Data Graph: SQL query history, BI semantics, lineage, and business glossaries. AI bootstraps 90% of the context from those signals; domain experts contribute the final 10%, which is business logic, exceptions, and tribal knowledge. One insurance customer compressed a twelve-month documentation build into a single month using this pipeline. CME Group cataloged 18 million assets and defined 1,300+ glossary terms in their first year with Atlan.
The context-aware AI agent architecture at scale requires this cross-platform approach. Atlan’s Enterprise Data Graph spans 400+ data sources across warehouses, BI, SaaS, ERP, and CRM. Every agent framework consumes the same governed context endpoint via MCP. For the full implementation path, see how to implement a context layer.
Frequently asked questions
Permalink to “Frequently asked questions”1. What is the difference between context layer design and context layer implementation?
Permalink to “1. What is the difference between context layer design and context layer implementation?”Design covers the architectural decisions made before any tooling is selected: shared vs. per-agent substrate, governance model, portability requirements, lifecycle policy. Implementation covers the build steps that follow. Design decisions made implicitly during implementation default to wrong choices: per-agent context, platform-native scope, no lifecycle policy. All are recoverable but increasingly costly to reverse.
2. When is a platform-native context layer sufficient?
Permalink to “2. When is a platform-native context layer sufficient?”Platform-native context is genuinely sufficient in three cases: the organization is fully consolidated on one data platform, agents require only single-platform queries, and there are no cross-system governance requirements. Outside those conditions, platform-native context fails on the most valuable enterprise queries: those that cross warehouse, CRM, and ERP boundaries. The enterprise context layer case is strongest for regulated industries, multi-system data estates, and organizations building more than one agent.
3. Does MCP replace the need for a context layer?
Permalink to “3. Does MCP replace the need for a context layer?”MCP is a protocol, not a context layer. It is the delivery mechanism through which a context layer exposes governed metadata to agent frameworks. What sits behind the MCP server determines outcome quality: a governed context graph with certified definitions and lineage produces fundamentally different results than a raw schema exposed via the same protocol. For a detailed comparison, see MCP vs. proprietary API.
4. How is context layer design different from context engineering?
Permalink to “4. How is context layer design different from context engineering?”Context engineering is the ongoing discipline of selecting, structuring, and delivering context to agents at runtime. Context layer design is the one-time architectural decision layer that precedes it. Good design makes context engineering efficient; poor design forces engineers to compensate with increasingly complex retrieval pipelines. The four context engineering strategies all assume a well-designed context layer exists underneath them.
5. What types of AI agent memory does a context layer provide?
Permalink to “5. What types of AI agent memory does a context layer provide?”A context layer provides semantic memory and procedural memory at the infrastructure level: business definitions, lineage, governance rules, and organizational ontology that persist across sessions and are shared across agents. For the full taxonomy, see types of AI agent memory and memory layer vs. context layer. The business context for AI that a context layer provides is the shared, persistent layer; agent-specific memory sits on top of it.
6. What context management strategies work best at enterprise scale?
Permalink to “6. What context management strategies work best at enterprise scale?”The most durable context management strategies treat context as infrastructure, not configuration. That means a shared substrate governed centrally or federally, exposed via open protocols, and updated through defined ownership workflows. Point solutions (per-agent RAG pipelines, static documentation exports, knowledge base integrations) work for single use cases but do not compose into a platform for context-aware AI agents at enterprise scale.
Sources
Permalink to “Sources”- Atlan AI Labs. “Enhanced Metadata Improves Query Accuracy.” https://atlan.com/know/enhanced-metadata-improves-query-accuracy/ (522 queries, p < 0.0001, 38% SQL accuracy improvement)
- Snowflake. “Agent Context Layer for Trustworthy Data Agents.” https://www.snowflake.com/en/blog/agent-context-layer-trustworthy-data-agents/ (20% accuracy improvement, 39% tool call reduction)
- Gartner Research Notes (five reports, May 2026). Referenced in Atlan PoV materials. Design principles: framework-agnosticism, protocol-driven architecture, provenance-first. Projection: 60% of MCP-only agentic analytics projects will fail by 2028.
- Allen Chan. “AI Agent Anti-Patterns Part 1.” Medium, 2025. Context isolation documented as a top architectural pitfall.
- DataHub. “Context Layer for AI.” https://datahub.com/blog/context-layer-for-ai. Anti-pattern: “The most common mistake is treating context as a one-time implementation.”
- arXiv. “Agentic Context Engineering.” ICLR 2026. Semantic continuity principle; Minimal Sufficiency Principle.
- arXiv. “Context Engineering 2.0.” 2025. Optimized context format performance vs. verbose catalogs.
- Datadog. “State of AI Engineering Report.” 2026. 69% of input tokens in enterprise LLM traces spent on system prompts.
- Workday. Joe DosSantos, VP Enterprise Data and Analytics. Quoted in Atlan case study materials.
- CME Group. Kiran Panja, Managing Director, Cloud and Data Engineering. Quoted in Atlan case study materials.
- Mastercard. Andrew Reiskind, Chief Data Officer. Quoted in Atlan PoV materials.
- Atlan. “Context Engineering Studio.” https://atlan.com/context-engineering-studio/
