



















Data fabric is the connective tissue that lets an AI agent read the whole business — not just the slice that lives in one warehouse. It does this by unifying data from diverse sources so an agent works from the full picture, not one system. Data fabric is a unified data architecture that connects, integrates, and governs data from diverse sources in real time, enabling data access across hybrid, multi-cloud, and edge environments while ensuring scalability, security, and compliance.
Data fabric explained
Permalink to “Data fabric explained”A data fabric is a composable, flexible and scalable way to maximize the value of data in an organization. It’s not one tool or process, rather an emerging design concept that gives a framework to think about how to stack existing tools, resources, and processes.
That it’s composable means that there’s no fixed architecture specific to data fabrics, a data fabric can be designed as a response to priority data needs of an organization. Just like the visual imagery that the name commands, we can imagine data fabric as a fluid piece of shapeless cloth touching all your data sources, types, and access points.
According to a recent study by Fortune business insights, The global data fabric market was valued at approximately USD 2.29 billion in 2023 and is projected to reach USD 12.91 billion by 2032, exhibiting a Compound Annual Growth Rate (CAGR) of 21.2% during the forecast period.
Let’s call on our friends at Gartner, and take a look at another definition:
“A data fabric utilizes continuous analytics over existing, discoverable and inferenced metadata assets to support the design, deployment and utilization of integrated and reusable data across all environments, including hybrid and multi-cloud platforms.”
Data fabric helps organizations manage huge amounts of data that are stored in different places and have different data types. They ensure unified data access, enable self-service and governance, and automate the data integration process. Below we will look at some of the differences between a data fabric and other popular concepts such as data virtualization, data mesh, and data lake/warehouse.
Data fabric vs data virtualization
Permalink to “Data fabric vs data virtualization”Data virtualization collects data from different storages and provides access to them in real-time. The main differences from data fabrics are use cases. Data virtualization is used for reports, business analytics, and visualization. Data fabric is used to analyze huge amounts of data, including IoT analytics, data science, real-time analytics, global analytics, fraud detection.
Also, read → Data fabric vs data virtualization
Data fabric vs data mesh
Permalink to “Data fabric vs data mesh”Unlike a data mesh, which stores datasets in different domains, a data fabric loads data into one place. The data fabric uses automation to discover, connect, recognize, and deliver data to consumers, while the data mesh uses domain owners to do this.
Also, read → Data fabric vs data mesh
Data lakes vs data warehouses
Permalink to “Data lakes vs data warehouses”Data lakes/warehouses are data storages that, like the date fabric, receive data from different sources. Data lakes and warehouses can form composable units of a data fabric, or serve as data sources in the data fabric. Unlike data lakes or warehouses, data fabric is not one single entity, rather a composition of different tools and processes.
How does data fabric work?
Permalink to “How does data fabric work?”The most popular data stacks involve cataloging, analysis, and modeling capabilities that are built on top of centralized stores such as data warehouses, data lakes, data lakehouses. While these can also drive great value, they may start feeling sluggish while dealing with an ever-growing amount of data. Among such disadvantages are:
- Data silos: In centralized approaches to process the data, you need to move it to central storage, which can cause a number of problems. Data transfer is often subject to data hosting and privacy policies, which are time-consuming to comply with and can significantly slow down data processing and analysis.
- Replication: Maintaining consistency of data across all repositories requires complex measures. In addition, more space is required to store replicas of the same data.
- Latency: With centralized approaches, all data from different sources are moved to one central repository. As the amount of data grows, the time required to move it increases, which causes a delay in the system.
Using the data fabric model avoids all of these problems. An important advantage of using a data fabric is that no data is moved in this model. It connects data from different sources, processes it, and prepares it for analysis. The data fabric also allows new data to be dynamically connected and interacted with. This allows you to significantly increase the speed of data processing and analysis.
Key components of a data fabric
Permalink to “Key components of a data fabric”- Augmented Data Catalog
- Persistance Layer
- Knowledge Graph
- Insights and Recommendations Engine
- Data Preparation and Data Delivery Layer
- Orchestration and Data Ops
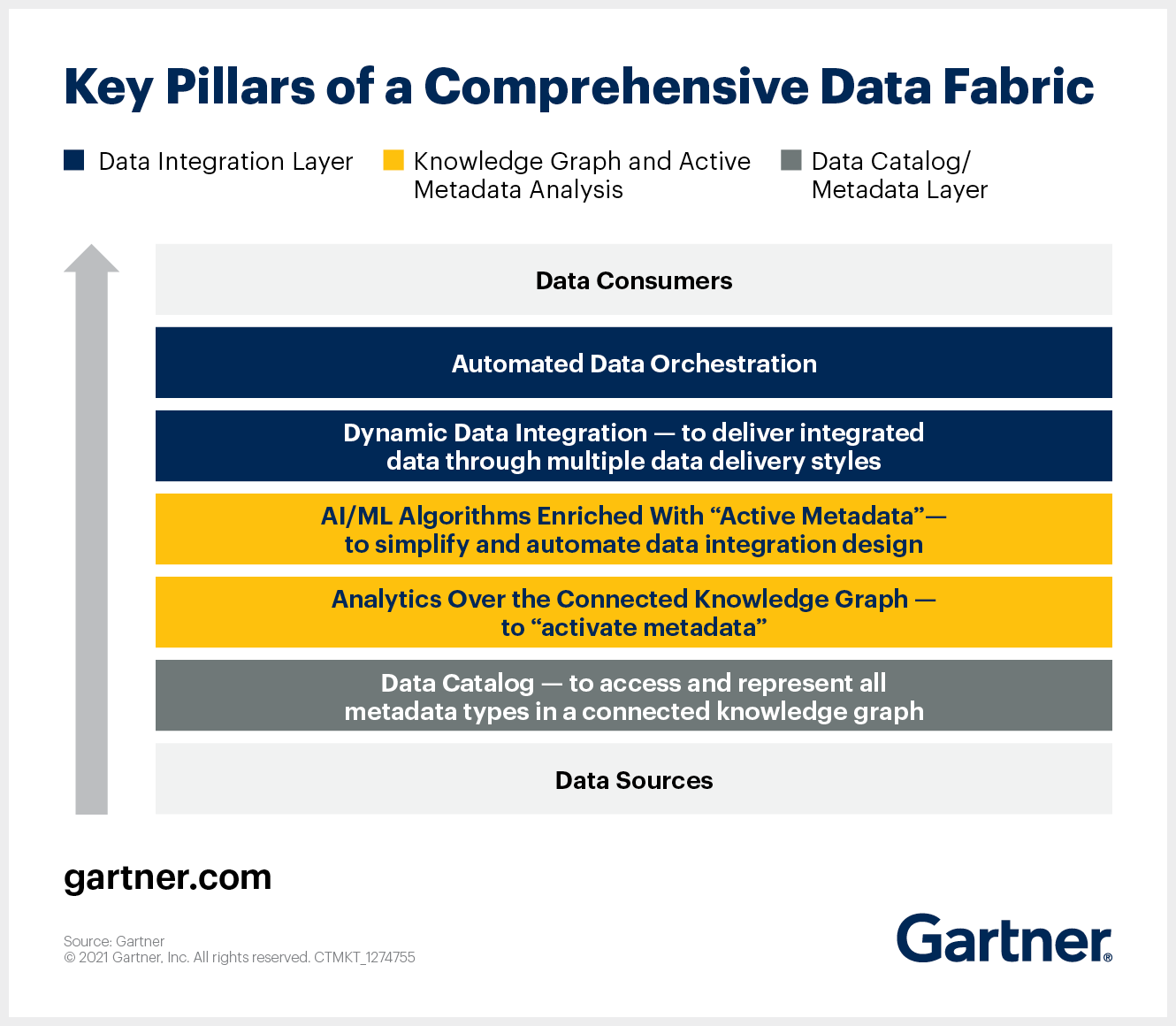
Key pillars of a comprehensive data fabric. Image by Gartner.
A data fabric is made up of components that can be selected and collected in various combinations. Therefore, the implementation of the data fabric may differ significantly. Let’s take a look at the main components of a data fabric.
- Augmented Data Catalog: Provides access to all types of metadata through a well-connected knowledge graph. It also graphically displays existing metadata in an easy-to-understand form and creates unique relationships between them. Augmented data catalogs form the business semantic layer for the data fabric by employing machine learning to connect data assets with organizational terminology.
- Persistence Layer: Dynamically stores data across a wide range of relational and non-relational models based on the use case.
- Active Metadata: A distinguishing component of a data fabric. Allows the data fabric to collect, exchange, and analyze all kinds of metadata. Active metadata includes metadata that records the continuous usage of data by systems and users other than passive metadata (design-based and run-time metadata).
- Knowledge Graph: Again another fundamental unit in data fabrics. They visualize a connected data environment using uniform identifiers, flexible schemas, etc. Knowledge graphs help understand the data fabric and make it searchable.
- Insights and Recommendations Engine: Creates reliable and robust data pipelines for both operational and analytical use cases.
- Data Preparation and Data Delivery Layer: Retrieves data from any source and delivers it to any target by any method: ETL (bulk), messaging, CDC, virtualization, and API.
- Orchestration and Data Ops: This component coordinates the work of all stages of the end-to-end workflow with data. It allows you to determine when and how often you should run pipelines and how you can control the data generated by those pipelines.
What do D&A leaders need to know about data fabric?
Permalink to “What do D&A leaders need to know about data fabric?”As a data and analytics leader, what are a few quick points you must know about this emerging design concept?
- Data fabrics operate across all kinds of environments like on-premise, cloud, multi-cloud, hybrid
- Data fabrics help deal with the inertia of moving data from one point to another
- Data fabrics reduce cost as they are likely to use the most accurate source of data
- Data fabrics are capable of significantly improving your data quality and data governance capabilities
- Data fabric is a single point of control for managing all your data, no matter how distributed and diverse your data is
Also, read → G2s 2024 Data Fabric Trends Report
What are the benefits of data fabric?
Permalink to “What are the benefits of data fabric?”- Efficient
- Democratization
- Scalability
- Integration
- Control
- Agility
A data fabric unifies access, loading, integration, and sharing of healthy data in a distributed environment. This enables organizations to maximize the value of their data and accelerate digital transformation.
The Recent Data Management & Data Fabric Market Study conducted by Unisphere Research and Radiant Advisors conducted in March 2024 revealed that 26% of organizations recognize the benefits of data fabric for IT data management, while 6% see its advantages for business analytics and discovery.
The main benefits of the data fabric model are explained below.
- Efficiency: A data fabric can aggregate information from previous queries, allowing the system to scan the aggregated table instead of the raw data in the backend. Allowing requests to access smaller datasets than them scanning the raw data of the entire store also eliminates the problem of multiple concurrent requests due to the higher speed of each individual request. The data fabric can dramatically reduce query response times, allowing enterprises to respond quickly to critical questions.
- Democratization: Data fabric provides data virtualization to help organizations implement seamless access to data while democratizing data. When organizations adopt a data fabric architecture, they create an environment in which data access and sharing are faster and easier because business users can access the data with minimal IT involvement. When properly constructed, logical data fabrics also centrally provide the necessary security and data management.
- Scalability: Data fabric is a persistent and scalable solution for managing all of your data in a single environment. It provides great scalability that can adapt to the growth of data, data sources, and applications.
- Integration: The data fabric will integrate data from multiple sources, cleanse that data and ensure its integrity, and analyze and share reliable data with stakeholders.
- Control: The data fabric provides comprehensive access to data and its use within the same organization, which allows you to create useful predictions and increase system performance.
- Agility: Data fabrics offer features for virtualizing data access in the enterprise, allowing information flexibility. It is also possible to combine queries against external data sources such as other databases, web services, files to execute queries without costly data movement.
Data fabric use cases
Permalink to “Data fabric use cases”Here are a couple of examples of data fabric use cases:
One would be creating a holistic customer view, as explained in this article. Data fabric can enable organizations to bring together data from all interaction points of the customer. It adds to better knowledge of the customer, thus propelling seamless real-time personalization and customization initiatives.
Data fabric can also power what’s called the data marketplace. These would reduce duplicate work, rather data teams could shop for existing infrastructures that power their specific use case.
How organizations making the most out of their data using Atlan
Permalink to “How organizations making the most out of their data using Atlan”The recently published Forrester Wave report compared all the major enterprise data catalogs and positioned Atlan as the market leader ahead of all others. The comparison was based on 24 different aspects of cataloging, broadly across the following three criteria:
- Automatic cataloging of the entire technology, data, and AI ecosystem
- Enabling the data ecosystem AI and automation first
- Prioritizing data democratization and self-service
These criteria made Atlan the ideal choice for a major audio content platform, where the data ecosystem was centered around Snowflake. The platform sought a “one-stop shop for governance and discovery,” and Atlan played a crucial role in ensuring their data was “understandable, reliable, high-quality, and discoverable.”
For another organization, Aliaxis, which also uses Snowflake as their core data platform, Atlan served as “a bridge” between various tools and technologies across the data ecosystem. With its organization-wide business glossary, Atlan became the go-to platform for finding, accessing, and using data. It also significantly reduced the time spent by data engineers and analysts on pipeline debugging and troubleshooting.
A key goal of Atlan is to help organizations maximize the use of their data for AI use cases. As generative AI capabilities have advanced in recent years, organizations can now do more with both structured and unstructured data—provided it is discoverable and trustworthy, or in other words, AI-ready.
Tide’s Story of GDPR Compliance: Embedding Privacy into Automated Processes
Permalink to “Tide’s Story of GDPR Compliance: Embedding Privacy into Automated Processes”- Tide, a UK-based digital bank with nearly 500,000 small business customers, sought to improve their compliance with GDPR’s Right to Erasure, commonly known as the “Right to be forgotten”.
- After adopting Atlan as their metadata platform, Tide’s data and legal teams collaborated to define personally identifiable information in order to propagate those definitions and tags across their data estate.
- Tide used Atlan Playbooks (rule-based bulk automations) to automatically identify, tag, and secure personal data, turning a 50-day manual process into mere hours of work.
Book your personalized demo today to find out how Atlan can help your organization in establishing and scaling data governance programs.
Conclusion
Permalink to “Conclusion”In this article, we have explored what is a data fabric, its main components, and the benefits of fashioning one for your organization.
A data fabric should be used when an organization requires a centralized platform to access, manage and govern all data. The first step is to design a data governance framework that makes sense for your organization. The next step is implementation, which involves deploying a platform that:
- Consolidates all metadata, with context, in a single repository
- Enables active metadata management
- Ensures granular access control and governance
- Empowers open collaboration and sharing of data
That’s where a modern data catalog and governance platform like Atlan can help.
FAQs about Data Fabric
Permalink to “FAQs about Data Fabric”1. What is data fabric?
Permalink to “1. What is data fabric?”Data fabric is a unified architecture that identifies, connects, and optimizes data from disparate sources. It reveals relationships between various data types, enabling organizations to derive actionable insights efficiently. By doing so, data fabric facilitates a more dynamic and holistic approach to managing enterprise data.
2. How does data fabric differ from data mesh or data lake?
Permalink to “2. How does data fabric differ from data mesh or data lake?”While data lakes store vast amounts of raw data and data mesh emphasizes decentralized ownership, data fabric focuses on connecting data across platforms and locations. It integrates diverse data systems, providing a cohesive framework for real-time data access, unlike the other two approaches that target specific data management challenges.
3. What are the benefits of adopting a data fabric approach?
Permalink to “3. What are the benefits of adopting a data fabric approach?”Adopting data fabric offers multiple benefits, including enhanced data accessibility, improved real-time analytics, and streamlined compliance. It simplifies data integration across hybrid and multi-cloud environments, enabling faster decision-making and reducing operational complexity.
4. How can I implement a data fabric architecture?
Permalink to “4. How can I implement a data fabric architecture?”Implementing a data fabric requires identifying key data sources, integrating them using intelligent tools, and establishing governance frameworks. Organizations often leverage AI and machine learning to automate data discovery, curation, and real-time integration.
5. Which platforms or tools support data fabric strategies?
Permalink to “5. Which platforms or tools support data fabric strategies?”Popular platforms supporting data fabric include IBM Cloud Pak for Data, Talend Data Fabric, and Informatica. These tools offer features like data integration, governance, and real-time analytics, enabling businesses to deploy data fabric effectively.
6. How does data fabric enhance data security and compliance?
Permalink to “6. How does data fabric enhance data security and compliance?”Data fabric strengthens security by providing centralized control over data policies while enabling decentralized data access. It supports compliance through automated data lineage tracking, ensuring adherence to regulations like GDPR and CCPA.
