



















An agent inherits the governance rules of the data it reads. Without governance, agents leak data they shouldn’t. Data governance is the practice that sets those rules deliberately. It means assigning owners to your data, setting quality rules, automating compliance checks, and tracking trust for every data asset. Skip it, and the costs add up fast: poor data quality costs organizations an average of $12.9 million per year, according to Gartner research.
Without data governance, your teams spend their week arguing about which number is right, scrambling before compliance audits, and watching AI projects fail on flawed training data. Data governance fixes this by assigning clear owners to every data asset, setting quality and compliance standards, and automating enforcement. This makes it so data is trusted, compliant, and AI-ready by default.
Data governance at a glance
| Attribute | Detail |
|---|---|
| Definition | Assigning owners, setting standards, automating controls, measuring trust |
| Primary goal | Trusted, compliant, AI-ready data assets |
| Pilot timeline | 3–6 months for first domains |
| Full rollout | 18–24 months enterprise-wide |
| Cost of inaction | $12.9M/year average loss (Gartner) |
| Key components | Ownership, standards, lineage, observability, discovery, improvement loop |
| Regulatory triggers | GDPR, CCPA, EU AI Act, CSRD |
| Atlan recognition | Leader, Gartner Magic Quadrant for Metadata Management Solutions |
Different authorities define data governance differently. Here is how three of them put it:
| Source | Definition |
|---|---|
| DAMA International | The exercise of authority and control (planning, monitoring, and enforcement) over the management of data assets. |
| Gartner | The specification of decision rights and an accountability framework to ensure appropriate behavior in the valuation, creation, consumption, and control of data. |
| Atlan | The discipline of assigning data ownership, defining standards, automating controls, and measuring trust so every asset is ready for secure analytics and AI. |
All three definitions point to the same idea: someone needs to own the data, set the rules, and enforce them. DAMA frames this in terms of authority and control. Gartner centers it on who gets to make decisions about data. Atlan adds what modern teams actually need on top of that: data that is ready for AI.
Read on for 2026 stats, a 5-step starter guide, and real-world ROI examples. Well-governed metadata forms the certification layer of the enterprise context layer — the infrastructure that makes AI agents trustworthy in production rather than impressive only in demos.
Why do you need data governance?
Permalink to “Why do you need data governance?”Bad governance hits your budget in three places: regulatory fines, failed AI projects, and wasted analyst time. A 2024 Precisely/Drexel report found 67% of organizations don’t fully trust the data they use for decisions, up from 55% in 2023. Traditional, document-heavy governance can’t keep pace with modern data volume and AI demand.
Four specific cost centers show why this matters:
- Hidden costs: Poor data costs the average firm US $12.9 million a year in fines, re-work, and failed AI projects.
- Regulatory pressure: GDPR fines hit €1.2 billion in 2024, and the EU CSRD is expanding sustainability reporting requirements to thousands of large companies, with scope and timelines evolving under the Omnibus simplification package.
- AI failure spiral: According to MIT’s 2025 State of AI in Business report, 95% of enterprise Gen-AI pilots fail to deliver measurable P&L impact, often due to poor data readiness and flawed enterprise integration.
- Productivity drain: Data teams still lose a significant part of their week to hunting and cleaning datasets instead of building insights.
What are the core aspects of data governance?
Permalink to “What are the core aspects of data governance?”Six aspects make data governance work. Ownership makes clear who is responsible for what. Standards ensure everyone describes and measures data consistently. Automation enforces rules without slowing teams down. Observability spots quality problems before they spread. Discovery helps people find the data they need. And a continuous improvement loop keeps the program from going stale.
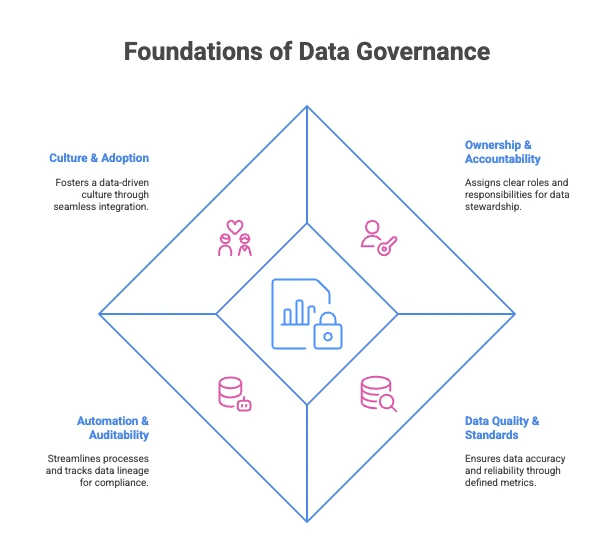
Foundations of Data Governance. Image by Atlan.
- Ownership and accountability: One named owner per asset, live RACI matrix in the data catalog, and steward leaderboards that celebrate rapid incident resolution.
- Common language and standards: Shared business glossary plus null-rate, freshness, and drift thresholds surfaced inline in BI, so users see a data trust badge before they click “Run.”
- Lineage-driven automation: Column-level lineage powers impact analysis; policy-as-code auto-tags PII, propagates quality scores downstream, and revokes access on breach.
- Observability and nudges: Trust dashboards update in real-time. Slack/Teams alerts fire the moment quality rules break, with a one-click fix link for stewards.
- Discovery and collaboration: Google-like search, in-context previews, and crowd-sourced wikis turn governance from gate-keeping into a shared, self-service knowledge hub.
- Continuous improvement loop: Quarterly policy reviews use usage analytics and stakeholder feedback to prune dead rules and automate the next 10% of manual tasks.
What are the goals of data governance?
Permalink to “What are the goals of data governance?”Every governance program should aim for six outcomes: fewer incidents, lower risk, steady compliance, higher data trust, faster analytics, and AI readiness. The best programs don’t just ask, “Do we have policies?” They ask, “Are those policies producing results?” Each goal below maps to a concrete metric you can track from day one.
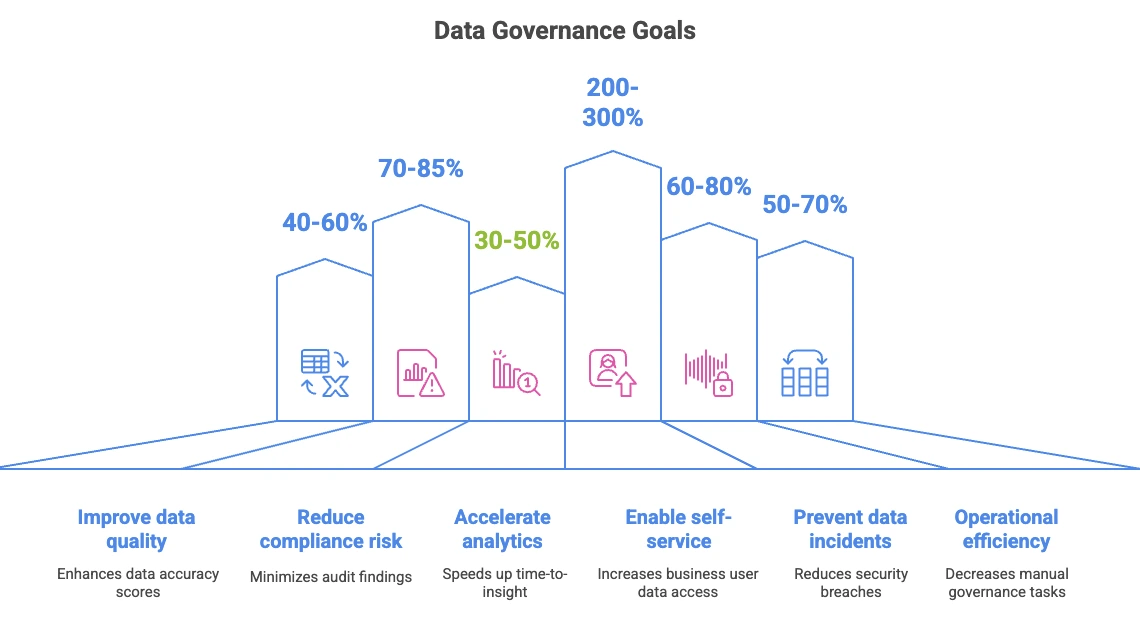
Data Governance Goals. Image by Atlan.
These outcomes define success for every modern data governance program.
| Goal | What “done well” looks like | Metric to track |
|---|---|---|
| Incident reduction | Minimal incident volume, rapid resolution | Mean time to detect/resolve data issues |
| Risk mitigation | Proactive breach, privacy, and operational risk control | Number of policy violations and near-misses |
| Compliance assurance | Continuous GDPR/CCPA/ISO alignment | Audit pass rate, compliance coverage % |
| Data trust | Verified accuracy, completeness, transparent lineage | Data quality score, trust badge adoption |
| Analytics speed | Instant discovery, shortened time-to-insight | Time-to-first-query, analyst search time |
| AI readiness | Bias-checked, context-rich training datasets | % of AI-ready assets in catalog |
How do you implement data governance?
Permalink to “How do you implement data governance?”Most programs fail because they try to govern everything at once. A better approach: pick three to five KPIs tied to your highest-risk data domains and build your pilot around those. A focused pilot can show value in three to six months. Full enterprise rollout usually takes 18 to 24 months. Start narrow, prove ROI, then scale.
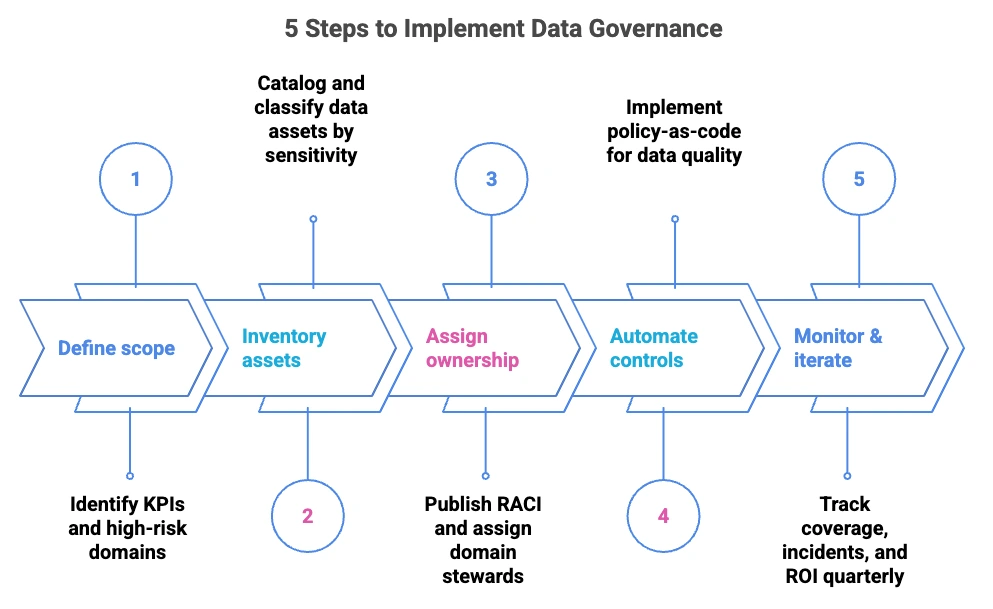
5 Steps to Implement Data Governance. Image by Atlan.
Here is a 5-step implementation guide to launch data governance that scales with your data and your team, with realistic timeframes:
- Define scope (Weeks 1–2): Link 3–5 KPIs to high-risk domains. Compliance-driven use cases, such as GDPR or CCPA alignment, tend to gain buy-in fastest.
- Inventory assets (Weeks 2–6): Auto-catalog and classify by sensitivity, criticality, and usage. Prioritize the domains you defined in step one before expanding further.
- Assign ownership (Weeks 4–8): Publish RACI; domain stewards own their assets, central team guides standards. Distribute stewardship to domain experts rather than creating dedicated full-time roles from day one.
- Automate controls (Months 2–4): Policy-as-code for quality, access, retention, and alerts. Automation handles classification and quality monitoring, so your team focuses on exceptions, not routine enforcement.
- Monitor and iterate (Ongoing, review quarterly): Live cockpit for coverage, incidents, and ROI. Use usage analytics and stakeholder feedback to prune dead rules and automate the next 10% of manual tasks each cycle.
Where you start matters. Compliance-driven use cases, such as GDPR or CCPA alignment, tend to gain buy-in faster. AI readiness programs take longer but deliver more long-term value.
Choose based on what your organization needs most right now.
Traditional vs. modern data governance
Permalink to “Traditional vs. modern data governance”Traditional governance was built for one warehouse and a small team of specialists. Modern governance covers distributed cloud systems, serves everyone from data engineers to business analysts, and uses automation to enforce rules that no manual process could keep up with. The gap is not just technical; it’s the difference between 6–18 months to value and 4–8 weeks.
| Dimension | Traditional governance | Modern governance |
|---|---|---|
| Architecture | Centralized data warehouse | Distributed cloud-native, multi-system |
| Ownership model | The central IT team owns all policies | Domain-distributed stewardship |
| Policy enforcement | Manual reviews, periodic audits | Policy-as-code, automated at ingestion |
| Discovery | Spreadsheet inventories | Automated catalog with AI-assisted tagging |
| Lineage | Manually documented | Column-level, automatically captured |
| Personas served | Data engineers, DBAs | Engineers, analysts, stewards, business users |
| Time to value | 6-18 months to coverage | 4-8 weeks to first meaningful value |
| AI readiness | Limited (built for the BI/reporting era) | Native (governs models, features, AI assets) |
How does data governance differ from data management?
Permalink to “How does data governance differ from data management?”Data governance decides the “what” and “who”: policies, standards, and ownership rules. Data management handles the “how” and “when”: daily operations, pipelines, and process execution. Governance is the blueprint. Data management is the crew that builds from it. You need both, and modern platforms are blurring the line between them.
| Dimension | Data governance | Data management |
|---|---|---|
| Focus | Policies, ownership, standards | Operations, tools, processes |
| Scope | Strategic framework | Tactical execution |
| Ownership | Business leaders, CDO, governance council | Data engineers, IT, data operations teams |
| Outputs | Policies, standards, RACI, data dictionary | Pipelines, storage systems, quality checks |
| Example activity | Defining what “active customer” means | Building the ETL that populates the customer table |
| Success metric | Policy coverage %, audit compliance | Data freshness, pipeline SLA, query latency |
Modern platforms blur this line through automation. When a data governance policy flows directly into the pipeline that enforces it, strategy and execution become one. Platforms with intelligent automation reach far higher governance coverage with fewer dedicated resources. Teams spend less time on manual enforcement and more on work that moves the business forward.
Data governance vs. data quality: quick comparison
| Data governance | Data quality |
|---|---|
| Sets the rules for what “good data” means in your organization | Measures and maintains data against those rules |
| Strategic: ownership, policies, access controls, lineage | Operational: null-rate checks, freshness, drift monitoring |
| Owned by business leaders, CDO, governance council | Owned by data engineers, stewards, platform teams |
| Success metric: policy coverage %, audit pass rate | Success metric: data quality score, SLA attainment |
| The standard | The daily work of meeting the standard |
What are the common data governance challenges?
Permalink to “What are the common data governance challenges?”Four challenges trip up most governance teams: unclear timelines, no dedicated stewards, hard-to-prove ROI, and hybrid cloud complexity. Each has a practical fix. None requires a perfectly clean data estate before you start.
1. Challenge: Determining the timeframe for data governance implementation
Permalink to “1. Challenge: Determining the timeframe for data governance implementation”Solution: Initial framework and pilot domains typically take 3–6 months. Full enterprise maturity can take 18–24 months. Success depends on starting with business-critical use cases and expanding gradually. Organizations that begin with compliance-focused initiatives often achieve faster stakeholder buy-in, while those that start with AI readiness achieve higher long-term value creation.
2. Challenge: Operating when the organization lacks dedicated data stewards
Permalink to “2. Challenge: Operating when the organization lacks dedicated data stewards”Solution: Modern governance distributes stewardship across domain experts rather than requiring dedicated full-time roles. Automation handles routine tasks like classification and quality monitoring, while business users contribute context through embedded workflows. Leading platforms enable substantially higher governance coverage with minimal dedicated resources through intelligent automation and community-driven collaboration.
3. Challenge: Measuring the return on investment (ROI) of governance initiatives
Permalink to “3. Challenge: Measuring the return on investment (ROI) of governance initiatives”Solution: Track direct cost avoidance (compliance fines, breach remediation), operational efficiency gains (reduced analyst search time, automated quality checks), and business value creation (faster time-to-insight, AI initiative success rates). Organizations typically achieve strong ROI within 18 months, measured by reduced compliance costs and increased operational efficiency.
4. Challenge: Implementing data governance across hybrid cloud environments
Permalink to “4. Challenge: Implementing data governance across hybrid cloud environments”Solution: Modern platforms provide unified control through metadata-driven approaches that abstract physical storage locations. Focus on consistent policy enforcement via API-driven integrations rather than tool consolidation. Leading implementations achieve consistent governance across on-premises, multi-cloud, and SaaS environments through active metadata layers that synchronize policies in real time.
How does data governance keep AI models reliable?
Permalink to “How does data governance keep AI models reliable?”AI models are only as good as the data behind them. 62% of organizations cite the lack of governance as a top obstacle to AI (Precisely / Drexel 2024). Only 12% say their data is ready for AI right now. Governance closes that gap by ensuring training data is checked for bias, traced through lineage, and compliant with policy before any model is built.
AI fundamentally changes governance requirements, demanding new approaches to traditional challenges while introducing risk categories that require proactive management.
- Bias detection through fairness dashboards: AI governance traces lineage down to raw features and runs automated bias checks on every prediction. Dashboards flag demographic skew the moment source data drifts and can auto-trigger a retraining workflow.
- Drift alerts as performance guardrails: Live input data is continually compared with the model’s training baseline. When the distribution shifts, the system creates an incident ticket and pings model owners, ensuring feature stores, model artifacts, and deployment configs stay within performance bounds.
- Audit snapshots for explainability compliance: Every model deployed stores a “model card” that captures the exact training dataset, feature list, and hyperparameters. These snapshots give regulators and stakeholders a full lineage trail from raw data to final prediction, meeting emerging AI audit and explainability rules.
- Input validation for continuous QA: Governance pipelines run schema, freshness, and outlier checks on every incoming batch before inference. Catching bad data upstream prevents silent corruption of production models and shifts quality assurance left in the ML lifecycle.
McKinsey’s 2025 State of AI report found that 88% of organizations now use AI in at least one business function. Yet only 39% report enterprise-level EBIT impact from AI, and most attribute less than 5% of their EBIT to AI use. Adoption is nearly universal, but measurable financial returns remain rare — a gap that governance can help close.
How Atlan approaches data governance
Permalink to “How Atlan approaches data governance”The challenge: governance that lives in documents, not in data
Permalink to “The challenge: governance that lives in documents, not in data”Most governance programs break down for a simple reason. Policies live in documents. Data lives in distributed systems. Stewards write rules that never reach the pipelines. Engineers build pipelines that never reflect the rules. As organizations grow, that gap grows with them. The result: compliance teams scrambling before audits, analysts who can’t trust the numbers they present, and AI projects stalled on data that was never ready to begin with.
The approach: governance as a control plane, not a documentation layer
Permalink to “The approach: governance as a control plane, not a documentation layer”Atlan works as an active metadata platform and control plane for data and AI governance. Instead of adding another documentation layer, it brings governance into the tools teams already use every day.
Automated classification and column-level lineage capture context at ingestion, with no manual tagging required. Policy-as-code enforcement pushes access rules, quality thresholds, and retention policies into pipelines at the point of data creation. Embedded collaboration surfaces governance context directly in Slack, Teams, and BI tools — so the right information shows up where decisions actually happen.
AI Governance Studio extends this to AI assets, tracking model lineage, bias metrics, and compliance status to help teams align with regulations like the EU AI Act. The result is a governance layer that enforces itself continuously, rather than relying on periodic manual review.
Customer outcomes
Permalink to “Customer outcomes”Atlan customers have cut central engineering workload by 53% (Kiwi.com) while improving data-user satisfaction by 20%. Austin Capital Bank launched new products with unprecedented speed while keeping sensitive data protected through advanced masking policies. Contentsquare consolidated thousands of assets into a single trusted home for every KPI and dashboard, improving data quality communication across all stakeholders.
Modernized data stack and launched new products faster while safeguarding sensitive data
"Austin Capital Bank has embraced Atlan as their Active Metadata Management solution to modernize their data stack and enhance data governance. Ian Bass, Head of Data & Analytics, highlighted, 'We needed a tool for data governance… an interface built on top of Snowflake to easily see who has access to what.' With Atlan, they launched new products with unprecedented speed while ensuring sensitive data is protected through advanced masking policies."

Ian Bass, Head of Data & Analytics
Austin Capital Bank
🎧 Listen to the podcast: Austin Capital Bank From Data Chaos to Data Confidence
53% less engineering workload and 20% higher data-user satisfaction
"Kiwi.com has transformed its data governance by consolidating thousands of data assets into 58 discoverable data products using Atlan. 'Atlan reduced our central engineering workload by 53% and improved data user satisfaction by 20%,' Kiwi.com shared. Atlan's intuitive interface streamlines access to essential information like ownership, contracts, and data quality issues, driving efficient governance across teams."
Data Team
Kiwi.com
🎧 Listen to the podcast: How Kiwi.com Unified Its Stack with Atlan

One trusted home for every KPI and dashboard
"Contentsquare relies on Atlan to power its data governance and support Business Intelligence efforts. Otavio Leite Bastos, Global Data Governance Lead, explained, 'Atlan is the home for every KPI and dashboard, making data simple and trustworthy.' With Atlan's integration with Monte Carlo, Contentsquare has improved data quality communication across stakeholders, ensuring effective governance across their entire data estate."

Otavio Leite Bastos, Global Data Governance Lead
Contentsquare
🎧 Listen to the podcast: Contentsquare's Data Renaissance with Atlan
Atlan was named a Leader in the Gartner Magic Quadrant for Metadata Management Solutions.
Frequently asked questions about data governance
Permalink to “Frequently asked questions about data governance”What is the difference between data governance and data quality?
Permalink to “What is the difference between data governance and data quality?”Governance sets the rules for what “good data” means in your organization. Data quality is the practice of measuring and maintaining data against those rules. Governance defines the standard. Quality is the daily work of meeting it.
What are the key components of a data governance framework?
Permalink to “What are the key components of a data governance framework?”A data governance framework has five parts. People, including data owners, stewards, and a governance council. Policies covering standards, classifications, and retention rules. Processes for ownership workflows and incident response. Technology such as a catalog, lineage, and classification tools. And metrics like quality scores and coverage rates. Start with people and policies. Technology comes after.
How long does data governance implementation take?
Permalink to “How long does data governance implementation take?”A pilot covering your first few domains takes 3 to 6 months. Full enterprise maturity takes 18 to 24 months. Compliance-driven starting points like GDPR alignment get buy-in faster. AI readiness programs take longer but create more long-term value. Executive sponsorship and early automation speed up both paths.
What is the difference between data governance and data management?
Permalink to “What is the difference between data governance and data management?”Governance defines the rules: who owns data, what quality standards apply, and how access works. Data management executes those rules by collecting, storing, transforming, and delivering data. One is the playbook. The other is game-day execution. You need both.
What is a data steward, and do I need one?
Permalink to “What is a data steward, and do I need one?”A data steward is the person responsible for the quality, documentation, and compliance of specific data assets. You don’t always need a full-time steward. Many programs give stewardship duties to domain experts who already know the data best. Automation handles the repetitive parts.
Why do data governance programs fail?
Permalink to “Why do data governance programs fail?”Four common reasons: no executive sponsor, trying to govern everything at once, treating governance as an IT-only project, or relying on manual processes that can’t scale. Programs that work start small with two to three critical domains, show ROI early, and automate step by step.
How does data governance relate to data compliance?
Permalink to “How does data governance relate to data compliance?”Compliance is a result of good governance, not a substitute for it. Governance builds the foundation with ownership, lineage, access controls, and quality standards. This foundation enables continuous compliance verification rather than scrambling before each audit.
What is active data governance?
Permalink to “What is active data governance?”Active data governance enforces policies automatically when data is created, moved, or accessed. It uses metadata, lineage, and policy-as-code to classify data, trigger alerts, and control access in real time. It replaces periodic manual reviews with a continuously running system.
How does Atlan support data governance?
Permalink to “How does Atlan support data governance?”Atlan is an active metadata platform that is a control plane for data and AI governance. It automates classification and enforces policies at scale. It captures column-level lineage and brings governance context into BI tools, SQL editors, and Slack. Atlan customers have cut central engineering workload by more than 50% while growing data adoption.
What is the ROI of data governance?
Permalink to “What is the ROI of data governance?”ROI shows up in three areas. First, cost avoidance through fewer fines and less breach remediation. Second, efficiency gains from less time searching for data and fewer manual checks. Third, business value from faster insights and more successful AI projects. Most organizations aim for strong returns within 18 months, tracked through analyst search time, compliance savings, and time-to-insight.
How does data governance support the enterprise context layer?
Permalink to “How does data governance support the enterprise context layer?”Data governance is the trust engine of the enterprise context layer. It defines which data assets carry certified definitions, who holds verified ownership, and which policies must be satisfied before AI can act on that context. Without governance, the context layer is populated with unreviewed metadata that models cannot rely on — producing confident but incorrect AI outputs. Atlan’s governance workflows are the Certify step in the Connect→Bootstrap→Certify→Activate pipeline, approving every business definition before it flows through the Atlan MCP Server to tools like ChatGPT, Claude, and Snowflake Cortex.
Ready to build a data governance program that sticks?
Permalink to “Ready to build a data governance program that sticks?”AI projects stall without data governance. Regulators penalize organizations that lack it. Some organizations report losses of more than $5 million due to poor data quality, and 7% estimate their losses at over $25 million.
Data governance prevents those losses. But modern governance is not about static documentation; it is an active, automated system that runs inside your daily workflows. Get the foundation right, and governance becomes the reason your AI investments actually pay off, your teams trust the numbers they present, and your compliance audits become a formality rather than a fire drill.
