



















The catalog is where an AI agent finds the right table to answer a business question — without it, the agent guesses. dbt’s native catalog gets part of the way there, but agents need governance and trust signals it does not carry across the full stack. According to dbt Labs’ 2025 State of Analytics Engineering report, over 56% of data professionals cite poor data quality as a key concern, a number that barely moves year over year, even as 80% of practitioners now use AI in their daily workflow.
The gap between transformation power and metadata visibility is real. A purpose-built data catalog layer on top of dbt helps close it.
Below is a breakdown of dbt’s native cataloging capabilities and what you need to add for comprehensive governance across your dbt assets.
Why does cataloging dbt assets matter?
Permalink to “Why does cataloging dbt assets matter?”dbt transforms data, but transformation alone doesn’t make data discoverable or trustworthy for downstream consumers. Cataloging your dbt assets solves three core problems: making documentation interactive and searchable, automatically capturing lineage so engineers understand impact, and giving business users enough context to trust what they’re using.
dbt, like many other tools in the modern data stack, was born out of a need to standardize model implementation for large-scale transformation workloads by better organization and templatization. More than 50,000 teams use dbt every week, and the community has surpassed 100,000 members. To get the most out of dbt, though, your assets need to be cataloged, documented, and discoverable.
Some reasons why data cataloging for dbt is non-negotiable:
- Efficient documentation: Smaller, distributed teams need shared clarity on business definitions to collaborate without constant back-and-forth. Without it, every analyst reinvents the same context from scratch.
- Accessible and discoverable documentation: In the world of data, efficient documentation isn’t just plain old text; it must be interactive. Data users should be able to explore data sources, entities, relationships, models, constraints, lineages, etc., which are searchable and discoverable via a data catalog.
- Automatic lineage capture: A dbt data catalog solution can automatically capture lineage, helping analysts and engineers understand the impact of changes. It ensures downstream consumers trust and understand the data assets being prepared for them. It improves the quality of data produced in addition to preventing errors and increasing efficiency.
dbt, with the workloads it encourages and supports, needs such a data catalog.
What dbt Catalog includes natively
Permalink to “What dbt Catalog includes natively”dbt Catalog is dbt Cloud’s built-in documentation and lineage tool, available on Starter and Enterprise plans. It provides model search, DAG visualization, table-level lineage, and documentation. Column-level lineage and multi-project lineage (dbt Mesh support) require Enterprise plans. dbt Core users have no access to Catalog; only static dbt Docs via dbt docs serve.
dbt Catalog native features: what’s included and what’s not
| Feature | Available in dbt Catalog | Plan required | Key limitation |
|---|---|---|---|
| Search and discovery | Yes | Starter (Catalog basic) | Primarily dbt-project discovery; expanded discovery includes Snowflake assets not managed by dbt (warehouse-specific, not cross-tool) |
| Table-level lineage | Yes | Starter+ | Within dbt project only |
| Column-level lineage (CLL) | Available in the Catalog advanced | Enterprise (Catalog advanced) | No cross-tool CLL beyond dbt-managed assets |
| Model documentation | Yes | Starter+ | Static; no business glossary |
| Model performance and recommendations | Yes | Enterprise+ | dbt Cloud only |
| Multi-project lineage (dbt Mesh) | Yes | Enterprise (Catalog advanced) | Within dbt account |
| Business glossary | No | — | Typically requires a dedicated data catalog or governance platform |
| Cross-stack governance and RBAC | No | — | Typically requires a dedicated data catalog or governance platform |
| Cross-tool lineage (BI, warehouse, pipelines) | No | — | Typically requires a dedicated data catalog or governance platform |
| Business user and self-service layer | No | — | Technical-user focused |
dbt Catalog offers you a way to generate data model documentation automatically. This documentation provides you with the following features:
- Search and discovery for all data models in the dbt project
- Relationships between different entities and data models
- Finer details about columns, their types, allowed values, etc.
- The SQL script for any given entity or data model
- Table-level lineage for all data models in the dbt project
Let’s understand some of these capabilities in detail:
Column-level details in a data model
Permalink to “Column-level details in a data model”With the dbt data catalog, you get a descriptive tabular representation of all database object columns, including column descriptions, data types, column-level tests, allowed values, and more.
For instance, here’s the Columns section for the orders table in the jaffle_shop project.
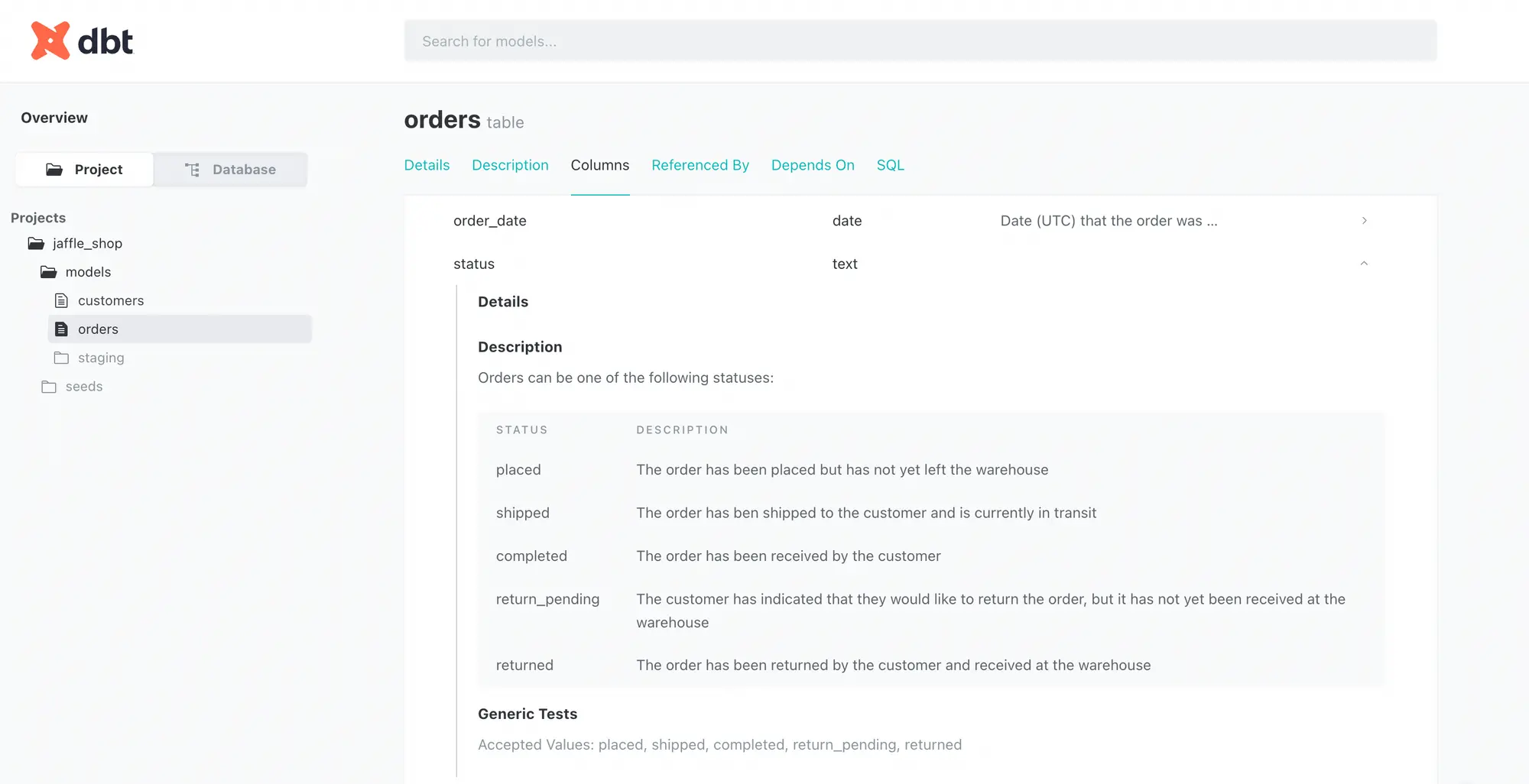
Column-level data dictionary in dbt. Source: dbt
Check out how the allowed values are enriched with a description so that anyone reading through the documentation can clearly understand the column’s purpose.
Search and discovery
Permalink to “Search and discovery”Menu-based navigation is handy, but it still leaves room for many use cases where business users, unaware of the database schema or the project structure, find it challenging to search for what they’re after.
Fortunately, dbt allows you to perform a full-text search on everything in the catalog using the search bar located at the top of the page, as shown in the image below:
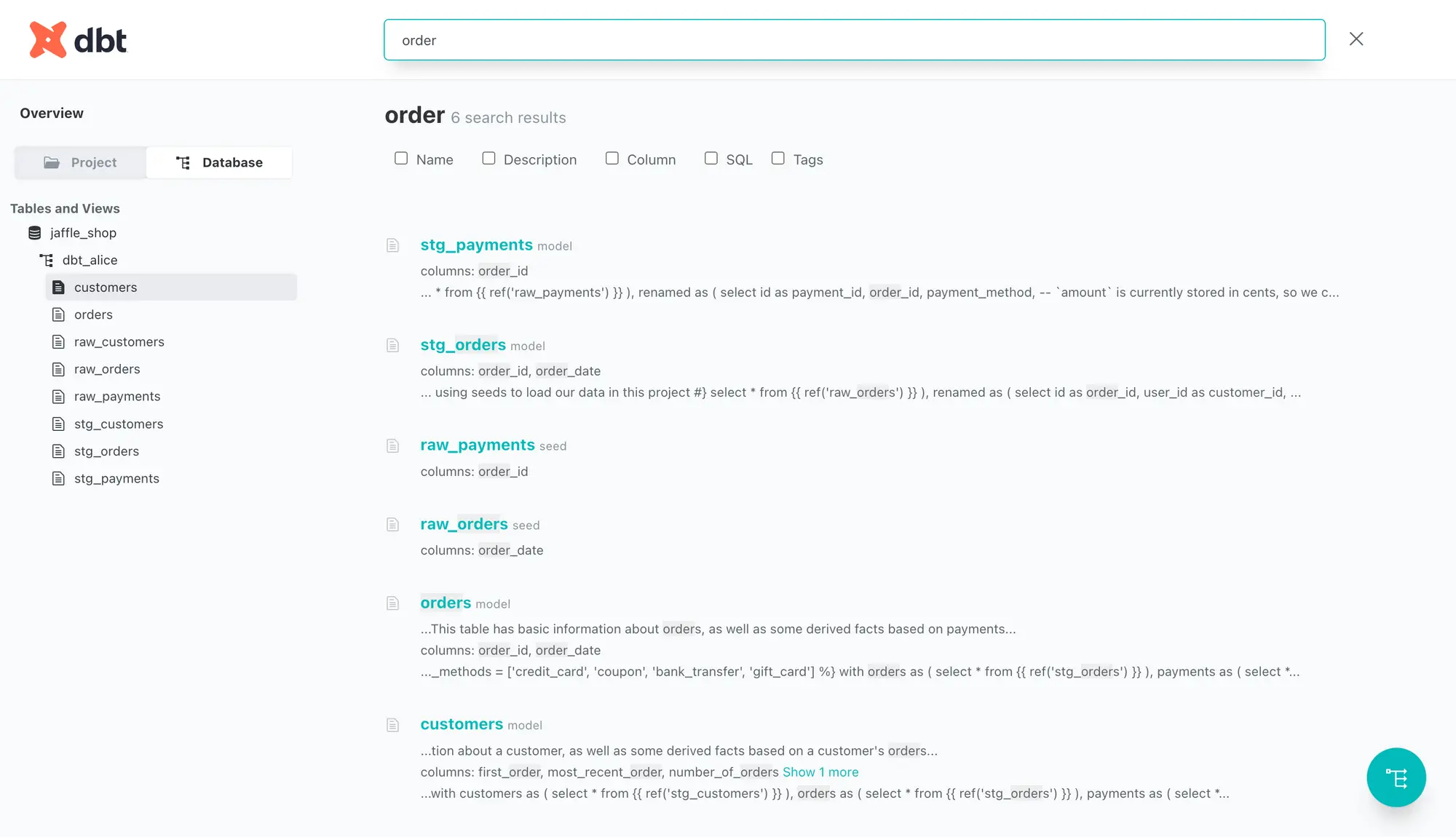
dbt provides native search to discover data assets. Source: dbt
The search feature also lets you search through specific subsets of information, such as names, descriptions, and tags.
Table-level data lineage
Permalink to “Table-level data lineage”Finally, the lineage graph is another great feature of the dbt data catalog. When you open the documentation page, you’ll find an icon that opens a full-size pop-up window with a lineage diagram describing the data transformation journey of your data:
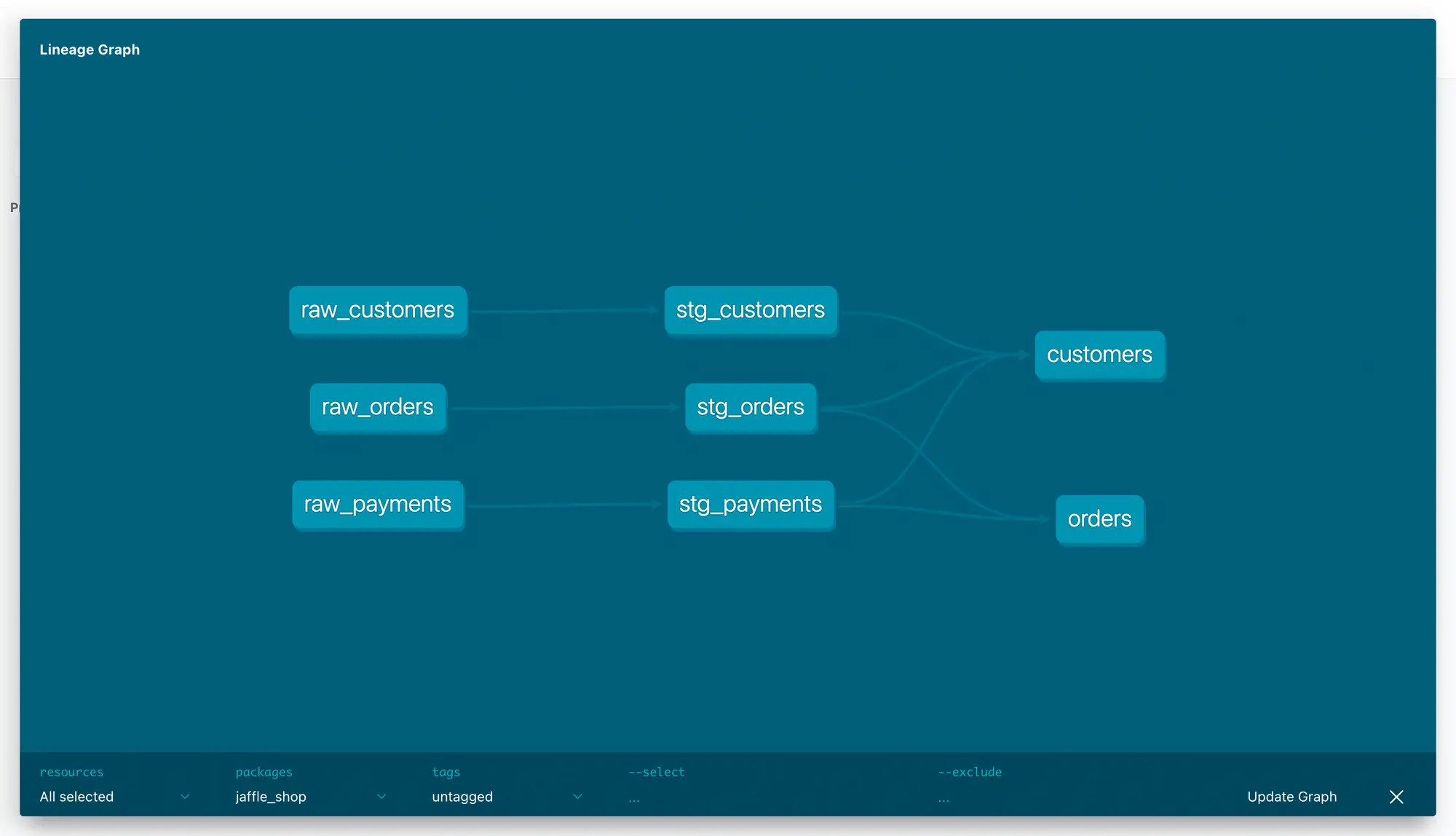
Understand how the data flows with dbt’s table-level data lineage. Source: dbt
The data lineage visualization builds on the depends-on and referenced-by fields that dbt maintains for every data model, based on your transformation workflow. You can customize the lineage graph by selecting the resources it uses to calculate the lineage:
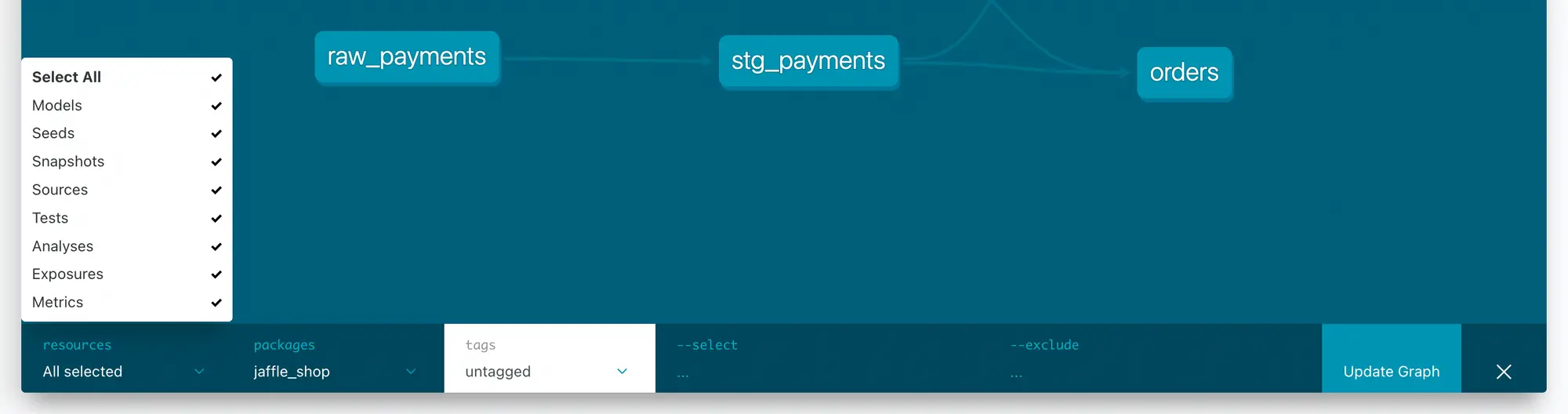
dbt data lineage customization. Source: dbt
dbt’s data catalog covers quite a bit of ground to make it worthwhile for developers and some data teams, especially dbt developers. Business teams typically need more context than dbt Catalog provides.
What should you look for beyond dbt’s native catalog?
Permalink to “What should you look for beyond dbt’s native catalog?”Once your dbt project scales beyond a single team, five capabilities become critical: cross-stack governance with classification and tagging, column-level lineage across tools (not just dbt models), AI-powered documentation automation, bi-directional metadata sync, and integration from source to consumption layer. None of these are available in dbt Catalog without a third-party tool.
dbt’s native data catalog ticks off some necessary features, such as search and discovery, table-level lineage, and metadata management.
It doesn’t, however, touch on critical areas such as data governance — which is precisely where a comprehensive data cataloging solution fills the gap.
Here are the data catalog capabilities you should evaluate when dbt Catalog’s native features aren’t enough:
- Data governance features, especially classification, tagging, and criticality
- Finer data lineage features, such as column-level lineage with custom metadata
- Automation of data cataloging, AI-powered workflows, personalization, and curation of metadata
- Ability to integrate across your data stack — right from the source layer to the consumption layer
- Bi-directional flow of metadata between your dbt data catalog and other preferred tools in your dbt workflow
1. Cross-stack governance: classification, tagging, and criticality
Permalink to “1. Cross-stack governance: classification, tagging, and criticality”dbt Catalog doesn’t include governance primitives — no classification, no tagging, no criticality scoring, no policy enforcement. Without them, data outside the dbt perimeter stays ungoverned, and compliance teams lose visibility into assets flowing through your warehouse, BI tools, or pipelines.
A data catalog built for dbt governance should let you assign ownership, tag columns by sensitivity or domain, set criticality scores on business-critical assets, and enforce data policies end to end. These primitives form the foundation for access-control decisions across your stack — not just within a single dbt project.
Without classification and tagging, analysts accessing data in Tableau or Power BI have no way to know whether a column contains PII or falls under regulatory scope — even if the underlying dbt model is well documented.
2. Cross-tool column-level lineage
Permalink to “2. Cross-tool column-level lineage”dbt Catalog provides column-level lineage within the dbt project on Enterprise plans, but your data doesn’t stop at dbt. It flows into Snowflake, BigQuery, Tableau, Looker, and Power BI. Cross-tool column-level lineage traces every transformation from the source system through the warehouse to the BI dashboard.
When a source column changes, column-level lineage across tools tells you exactly which downstream reports, dashboards, and ML features will break, before you merge. Without it, impact analysis requires manual tracing across systems and often involves multiple team handoffs.
dbt Catalog’s column-level lineage is bounded by the dbt account. A strong catalog integration extends that lineage graph to every tool in your stack.
3. AI-powered documentation, automation, and personalization
Permalink to “3. AI-powered documentation, automation, and personalization”Manual documentation doesn’t scale. According to the dbt Labs 2025 State of Analytics Engineering report, 50% of data practitioners already use AI for documentation and metadata development. A modern catalog should support AI-assisted documentation, automated tagging, and personalized asset views for each team role.
AI-assisted documentation accelerates analytics engineers by auto-generating column descriptions from SQL context, suggesting ownership assignments based on usage patterns, and surfacing relevant assets per role. Without automation, documentation debt compounds as your model count grows, and governance signals become unreliable for downstream consumers.
4. Cross-stack integration: source to consumption
Permalink to “4. Cross-stack integration: source to consumption”Your dbt models are one layer of a larger ecosystem that includes ingestion tools, warehouses, BI platforms, orchestrators, and observability tools. A comprehensive catalog integrates with every layer and gives every team member a single place to discover and understand data, regardless of where it lives.
dbt Catalog provides visibility into the dbt layer. But an analyst in Looker, a data steward in Snowflake, or a product manager in Amplitude each needs context that extends beyond dbt. Cross-stack integration means that dbt documentation, lineage, and governance decisions are visible wherever people actually work, not just inside dbt Cloud.
5. Bi-directional metadata flow
Permalink to “5. Bi-directional metadata flow”Metadata shouldn’t move in only one direction. Changes in your warehouse, BI tool, or governance layer should flow back into your catalog, and vice versa. Without bi-directional sync, dbt stays siloed from the rest of your stack, and teams operate on incomplete or stale context.
One-way metadata flow means that ownership changes made in Atlan don’t propagate back to dbt, and lineage updates from Snowflake don’t automatically appear in your catalog. Bi-directional sync keeps your dbt documentation, governance policies, and lineage continuously aligned with the rest of your stack, without manual reconciliation.
Capability gaps and risks
| Capability gap | Risk without it | How Atlan covers it |
|---|---|---|
| No cross-stack governance | Ungoverned data outside the dbt perimeter; compliance teams lose visibility | Classification, tagging, criticality scoring, and RBAC across your full stack |
| No business glossary | Business users can’t self-serve; definitions live in Slack and docs, not in the catalog | Searchable business glossary linked to dbt models, columns, and metrics |
| No bi-directional metadata | dbt stays siloed; ownership and governance changes don’t propagate across tools | Two-way metadata sync between dbt, warehouse, BI tools, and Atlan |
| No cross-tool column-level lineage | Lineage breaks at the warehouse boundary; impact analysis requires manual tracing | Column-level lineage from dbt source through warehouse to Tableau, Looker, Power BI |
How does Atlan bridge the gap for dbt data catalog?
Permalink to “How does Atlan bridge the gap for dbt data catalog?”Atlan integrates with dbt Cloud and dbt Core to catalog dbt assets alongside every other tool in your stack — warehouse, BI platforms, pipelines, and orchestrators. It adds cross-stack column-level lineage, a business glossary, enterprise RBAC, GitHub PR impact analysis, and AI-assisted documentation. Atlan is recognized as a Leader in the Forrester Wave for Enterprise Data Catalogs, Q3 2024.
In addition to significant improvements over what dbt offers in data cataloging, Atlan adds state-of-the-art data governance, data lineage, search, and discovery features. This helps you get a 360° view of your data across the board.
The result is a complete metadata layer. Analytics engineers document models faster with AI-assisted suggestions. Data stewards enforce governance policies that apply across dbt, Snowflake, and BI tools, not just inside the dbt project.
Business users discover, understand, and self-serve against dbt assets without needing to navigate the dbt project structure. And when a column changes upstream, every team member — from the engineer merging the pull request to the analyst using the downstream dashboard — knows the impact before it reaches production.
Some popular capabilities amongst users include:
- Active data governance
- End-to-end column-level lineage
- dbt metrics as an asset with their own profiles
- Embedded impact analysis in GitHub
- Building documentation standards right from dbt
- Exposing dbt documentation to your entire team
- Bringing dbt context into other tools
- Enabling self-service in data consumers and producers
Let’s look at these features in more detail.
Data governance for dbt
Permalink to “Data governance for dbt”Atlan’s data governance engine covers everything missing from the dbt data catalog. The extensive ownership and classification features help teams across the organization work with data more efficiently while accounting for all compliance and regulatory concerns.
A unified permissions model lets you connect dbt with other data sources without managing access rules separately.
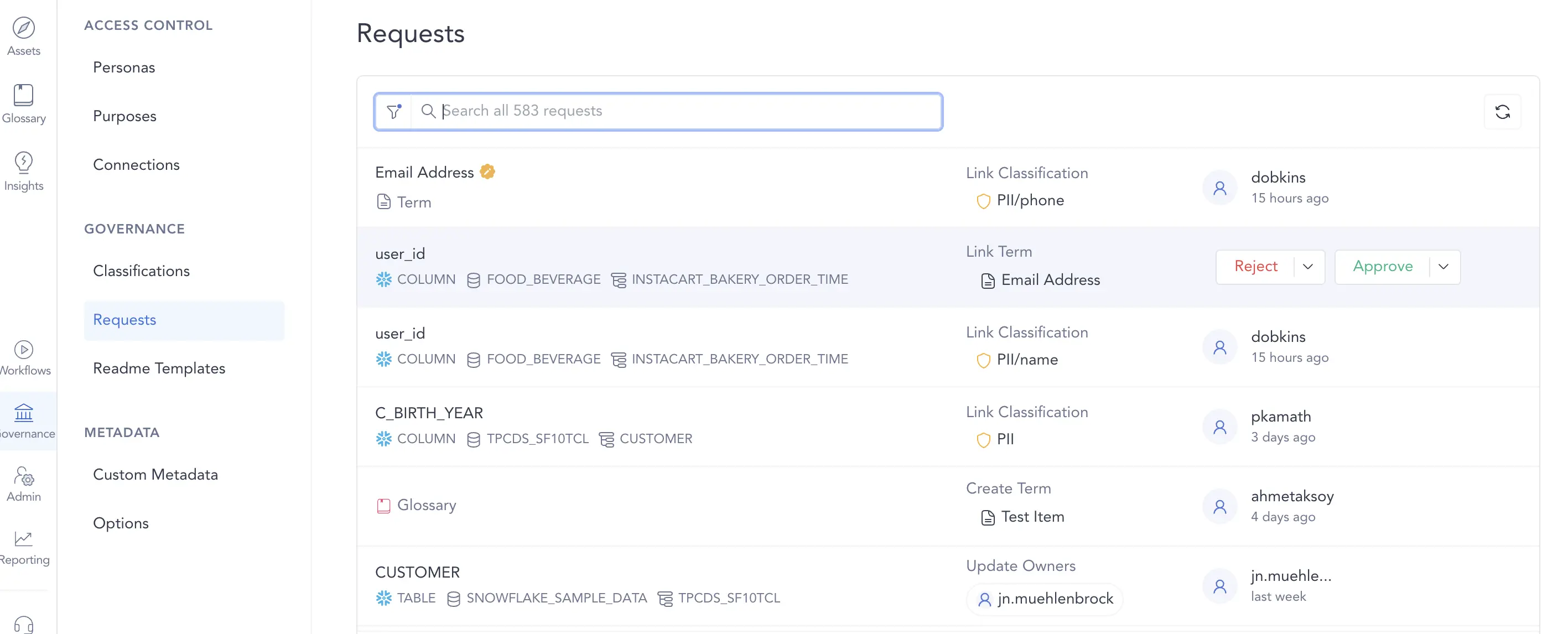
Atlan’s data governance for dbt data assets. Source: Atlan
Column-level lineage beyond dbt
Permalink to “Column-level lineage beyond dbt”To get a complete context and a 360° view of your data, you need to see how it flows end-to-end, from one system to the next. While dbt provides table-level data lineage, that isn’t enough for most business teams.
Atlan’s comprehensive column-level data lineage feature allows you to track lineage at the finest level with as much context as possible. With a smooth, interactive user interface, you can easily navigate data in any system across your organization.
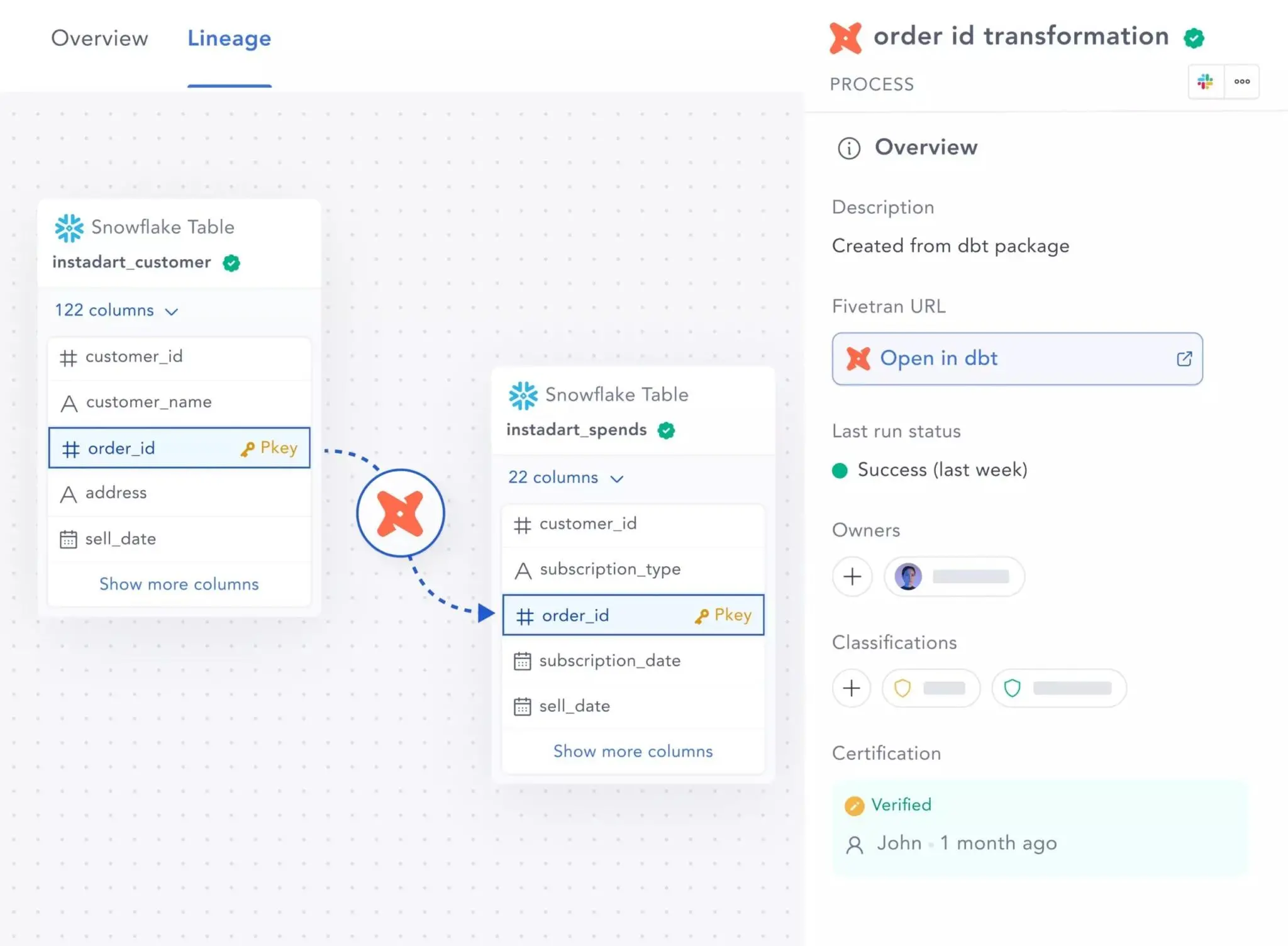
Atlan’s column-level lineage for dbt data assets. Source: Atlan
GitHub integration for impact analysis
Permalink to “GitHub integration for impact analysis”Atlan’s integration with GitHub solves collaboration challenges faced by data engineers who lack visibility around downstream usage of data assets and scramble to account for every change.
This integration enables data governance to move closer to the data creation process by helping data engineers understand how changes in a dbt model impact upstream assets.
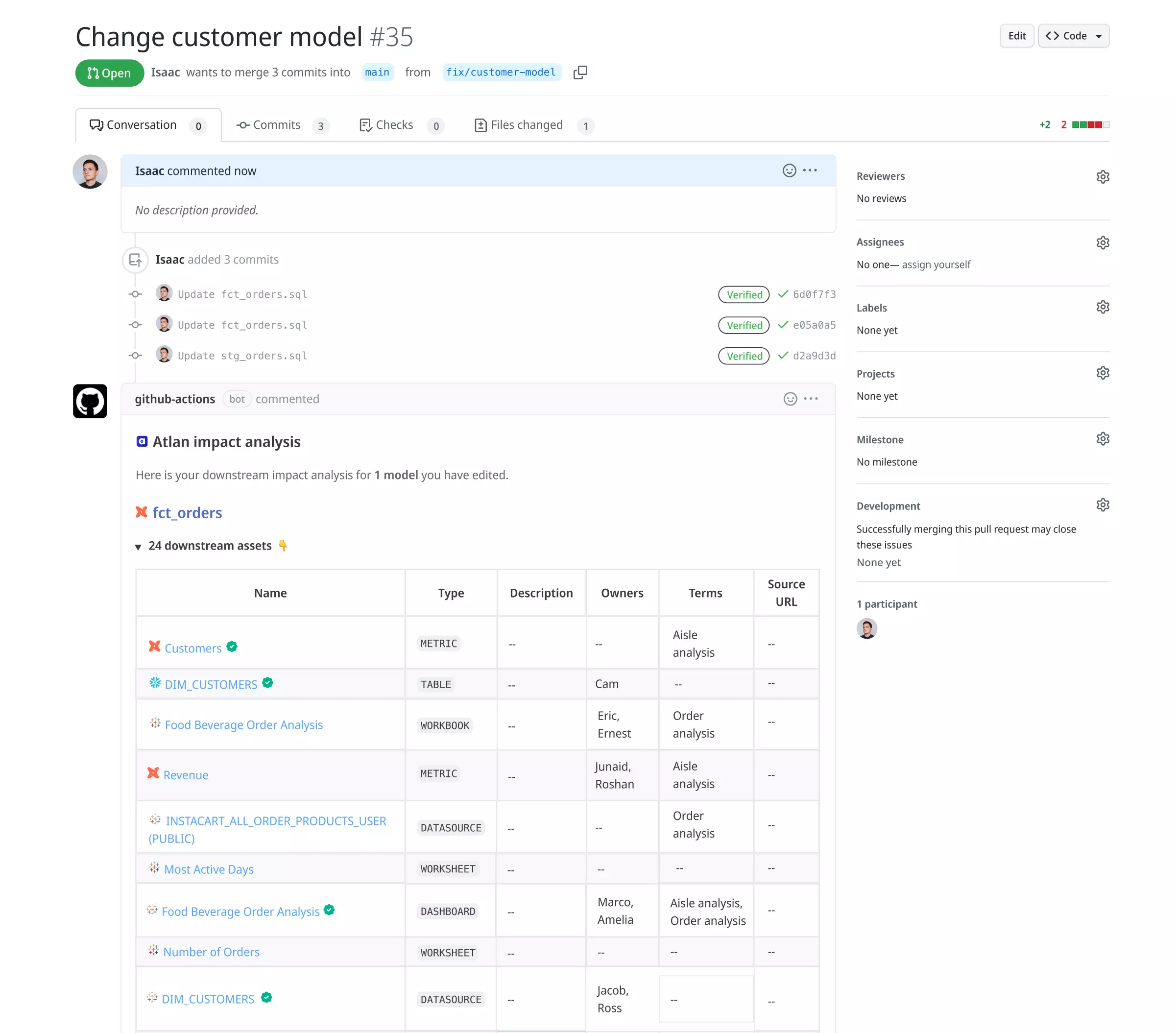
Atlan — GitHub integration — GitHub Actions screenshot. Image by Atlan
With Atlan and GitHub, data engineers can identify and collaborate with asset owners, and stakeholders can approve or disapprove changes impacting high-value assets.
Atlan brings lineage to GitHub, making it easy to see the impact of changes made to important data pipelines. Whenever someone opens a pull request to change a dbt model, the Atlan-GitHub action automatically creates a list of all downstream assets that will be impacted.
dbt metrics as first-class citizens on Atlan
Permalink to “dbt metrics as first-class citizens on Atlan”Atlan’s integration with the dbt Semantic Layer brings dbt’s rich metrics into the rest of the data stack. With this integration, company metrics are now part of a column-level lineage, spanning from data sources and data storage to transformation and BI tools.
Understand in detail how joint users benefit from this integration.
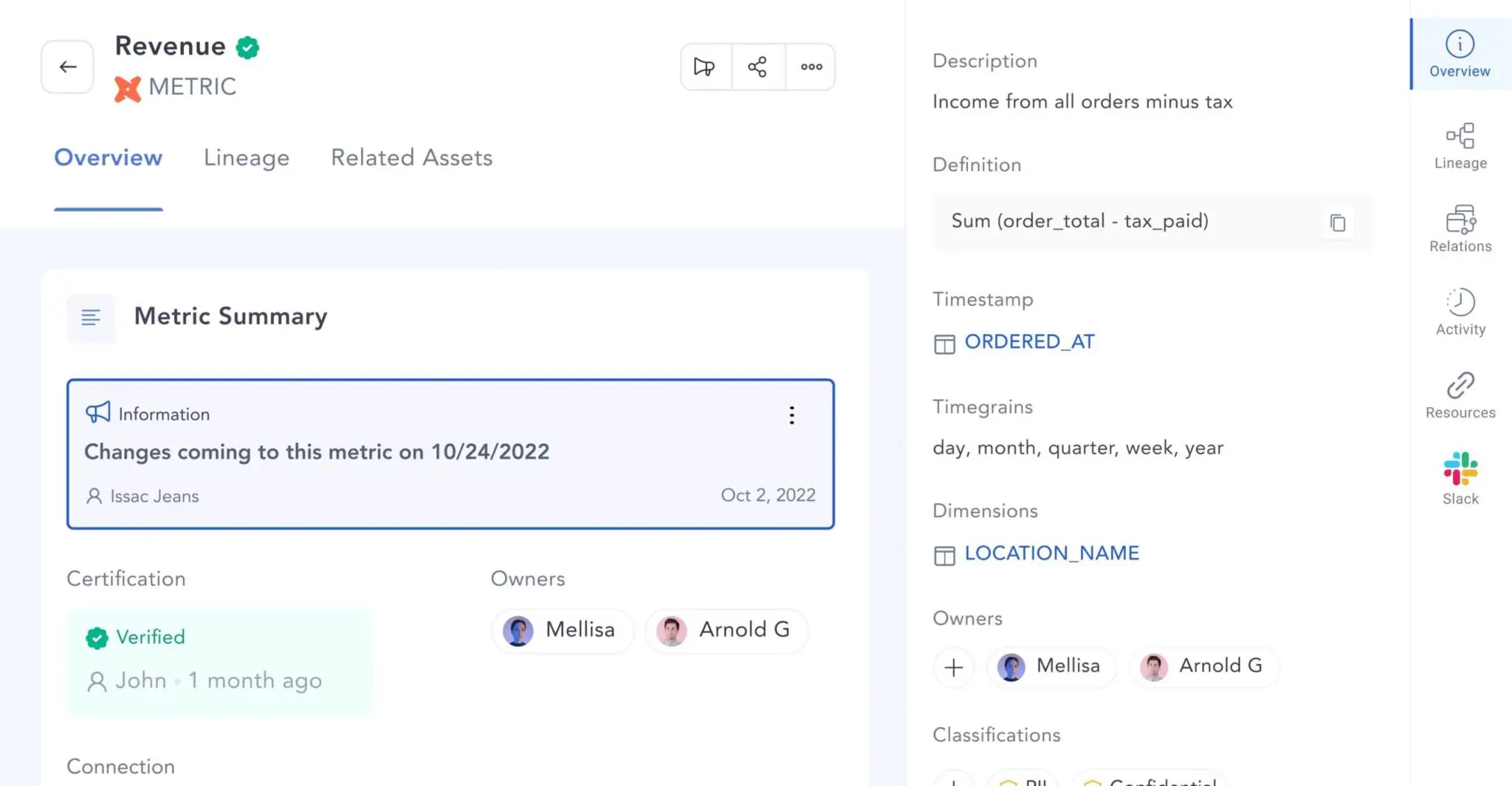
dbt metrics get their own 360° profile on Atlan. Source: Atlan
Building documentation standards right from dbt
Permalink to “Building documentation standards right from dbt”Atlan’s deep integration with dbt lets you create repeatable, metadata properties — table owners and verified tags — in your dbt models. It provides the base for sharing knowledge across your organization by standardizing documentation for developers.
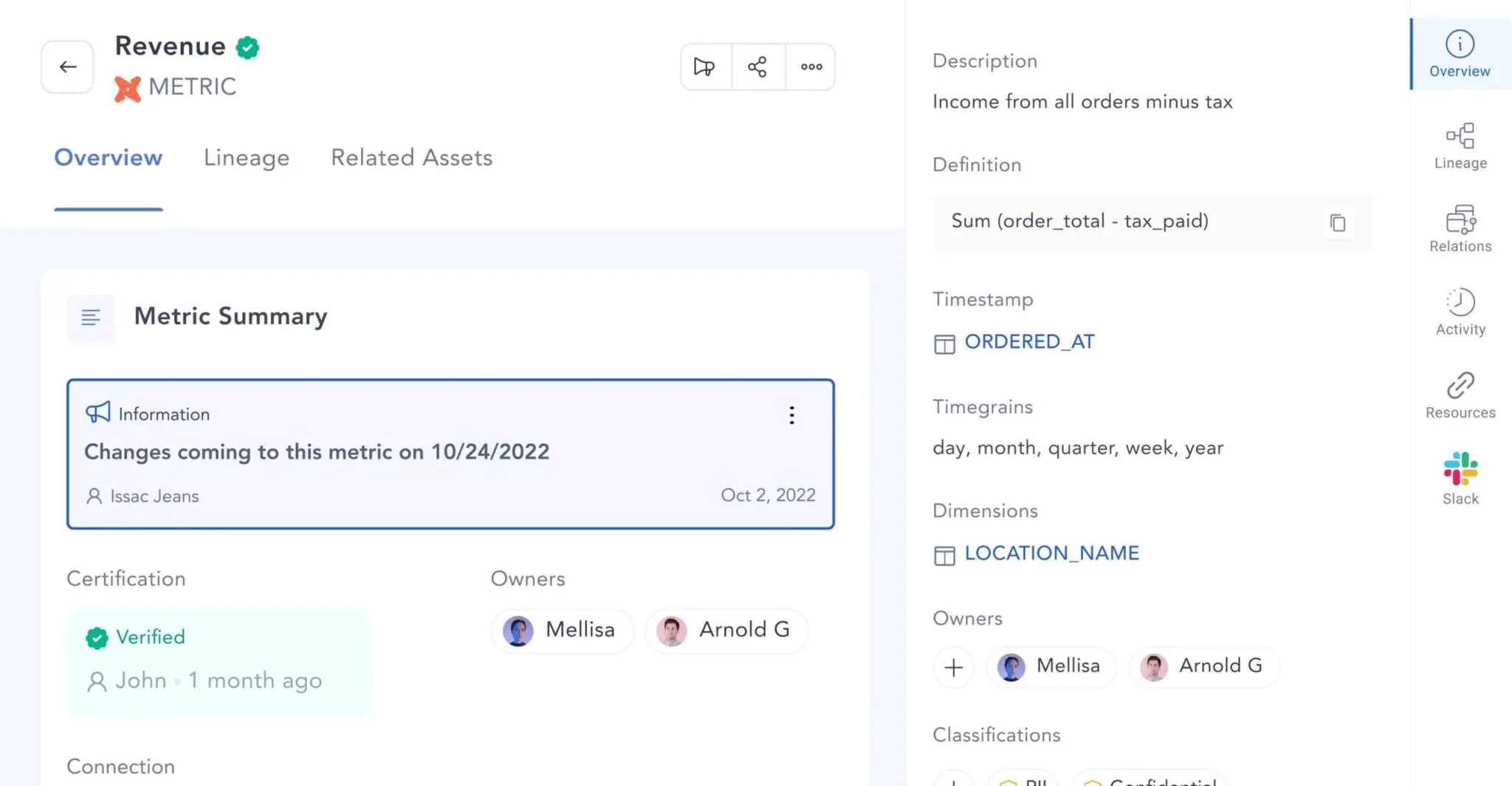
Business glossary and data dictionary — documentation for dbt data assets. Source: Atlan
Expose dbt documentation to your entire team
Permalink to “Expose dbt documentation to your entire team”With features like certification, freshness, relevance, and popularity, integrated with a Google-like search interface, Atlan supercharges your data discovery experience, saving you precious time sorting through documentation and scrambling for information via email and chat.
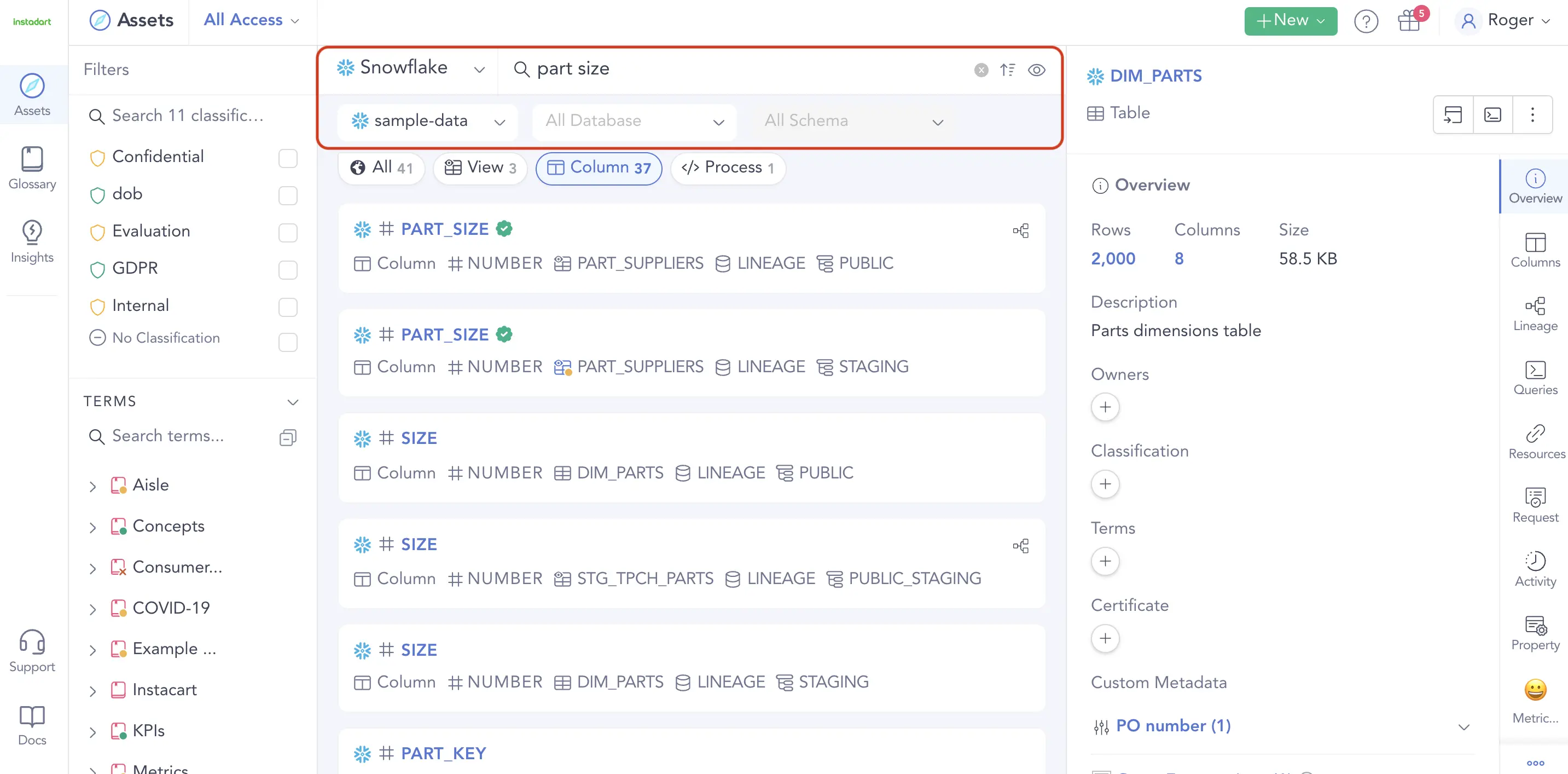
Search and discover assets through your entire data ecosystem. Source: Atlan
Bring dbt context to your tools (reverse metadata)
Permalink to “Bring dbt context to your tools (reverse metadata)”Atlan’s Chrome extension brings dbt metadata where you work. If you’re in a BI dashboard, you don’t have to go searching for context in dbt.
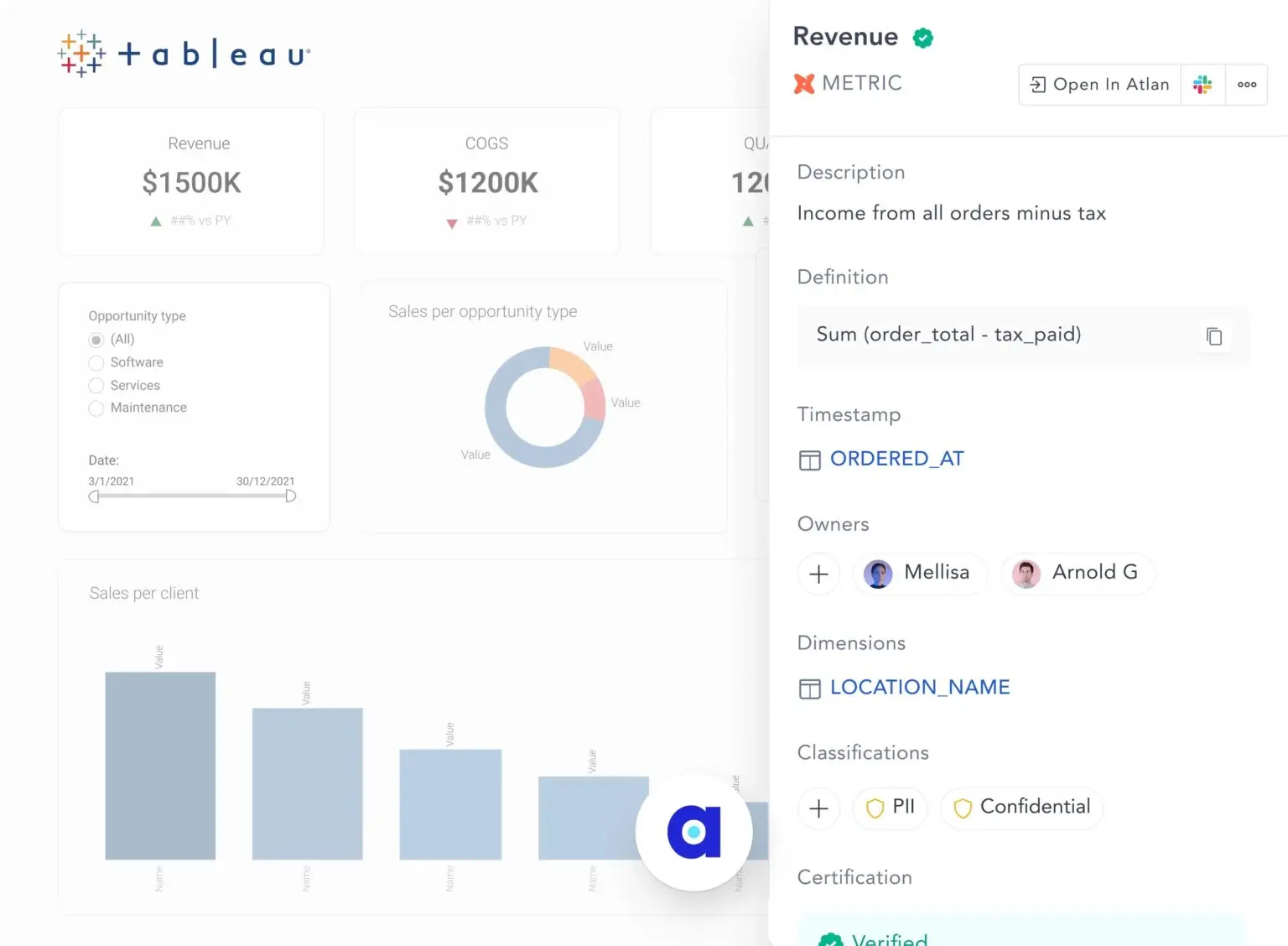
Access dbt metadata in the tools that you use every day. Source: Atlan
Enabling self-service in data consumers and producers
Permalink to “Enabling self-service in data consumers and producers”Atlan enables teams across the business to meet their data needs through self-service, a feature at the core of the modern data stack and its evolution to date. Capabilities such as intelligent automation, personalization, and custom metadata make Atlan more intuitive, flexible, and valuable to every team.
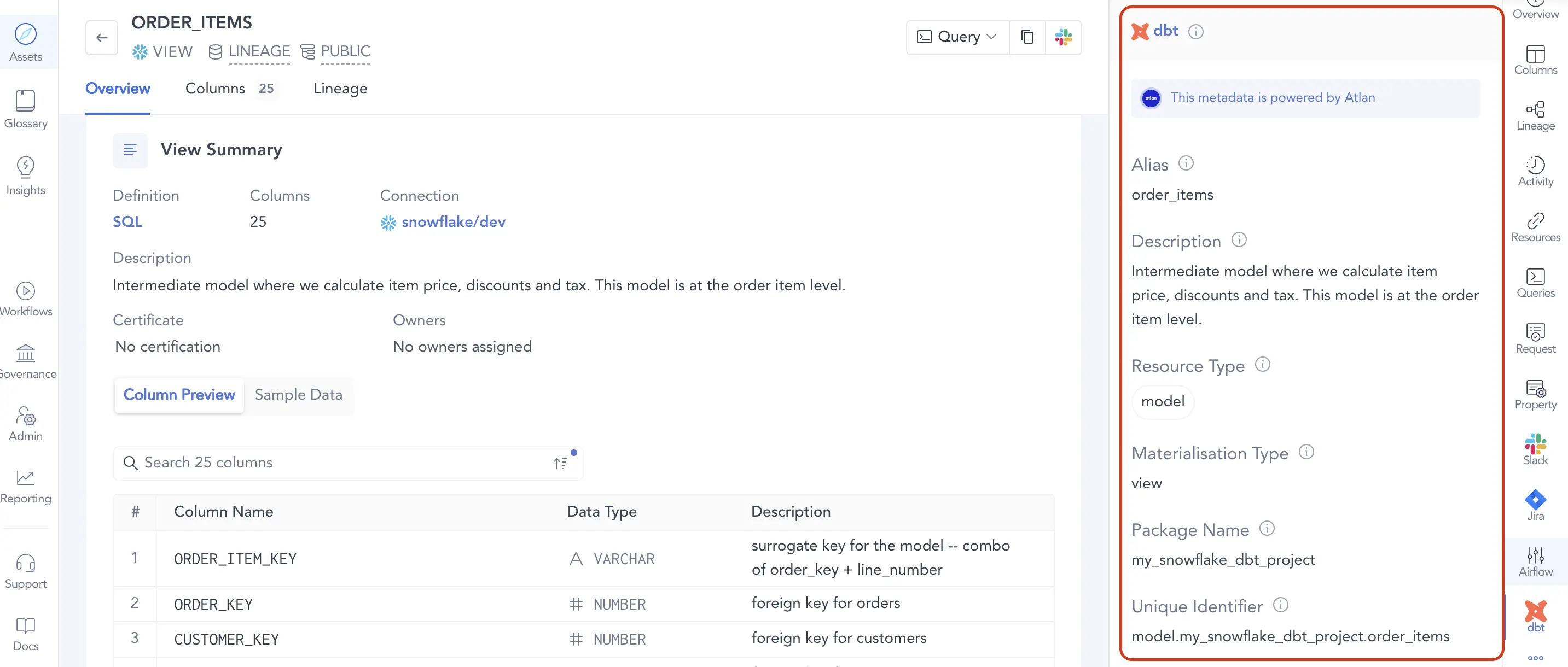
Self-service data discovery for everyone who wants to understand their business better. Source: Atlan
Atlan + dbt in the AI era
Permalink to “Atlan + dbt in the AI era”AI is only as good as the data behind it. Poor metadata leads to poor AI outputs.
Connecting Atlan to dbt turns your models, lineage, and business context into structured inputs that AI tools can actually work with. AI agents and co-pilots no longer rely solely on raw SQL. They govern and classify metadata that reflects how your organization uses its data in practice. Atlan’s AI-assisted documentation also helps analytics engineers document hundreds of tables faster. Governed metadata ensures downstream AI workflows pull from trusted sources.
In May 2025, dbt Labs announced the dbt Fusion engine as a next-generation engine for dbt development and compilation. Later in 2025, at Coalesce, dbt Labs announced the general availability of the remote dbt MCP server, designed to securely connect AI tools and agents to dbt’s structured context.
Both developments mean that the metadata layer connecting dbt to your catalog needs to be current, bi-directional, and AI-ready. Atlan’s integration keeps dbt context — lineage, documentation, governance tags — synchronized so that agentic workflows and AI co-pilots are working from trusted, governed metadata rather than raw, uncontextualized SQL.
This is especially relevant for teams exploring dbt data contracts and governed agentic workflows. As AI takes on a larger role in how teams build and consume analytics, the catalog layer that connects dbt to the rest of your stack determines whether AI outputs are trustworthy.
FAQ: dbt data catalog
Permalink to “FAQ: dbt data catalog”Does dbt have a built-in data catalog?
Permalink to “Does dbt have a built-in data catalog?”Yes. dbt Cloud includes dbt Catalog (formerly dbt Docs, then dbt Explorer) as its native documentation and lineage tool. It covers search, model docs, DAG visualization, and column-level lineage on Enterprise plans. dbt Catalog is available on Starter and Enterprise dbt Cloud plans. dbt Core users don’t have access to dbt Catalog.
What is dbt Catalog (formerly dbt Explorer)?
Permalink to “What is dbt Catalog (formerly dbt Explorer)?”dbt Catalog is dbt Cloud’s built-in knowledge base and lineage visualization experience. It lets you search and discover models, sources, and exposures. You can explore table and column-level lineage, monitor model performance, and get project health recommendations. It replaced dbt Docs and was renamed from dbt Explorer to dbt Catalog in 2025.
What does dbt Catalog include on the Enterprise plan?
Permalink to “What does dbt Catalog include on the Enterprise plan?”On Enterprise and Enterprise+ plans, dbt Catalog adds column-level lineage, multi-project lineage for dbt Mesh architectures, model performance analysis, and project recommendations. The Starter plan gives you search, documentation, and table-level lineage. Column-level lineage is not available on dbt Core self-hosted deployments.
What are the limitations of dbt’s native data catalog?
Permalink to “What are the limitations of dbt’s native data catalog?”dbt Catalog works within the dbt project boundary. It doesn’t automatically build end-to-end, cross-tool column-level lineage across dbt, your warehouse, and BI tools. It doesn’t include a business glossary, and it lacks enterprise RBAC for governing access across teams and domains. Business users who aren’t familiar with dbt’s project structure may also find navigation challenging.
How does Atlan extend dbt Catalog?
Permalink to “How does Atlan extend dbt Catalog?”Atlan integrates with both dbt Cloud and dbt Core to catalog dbt assets alongside your warehouse, BI tools, and pipelines. It adds cross-stack column-level lineage, enterprise governance with classification and tagging, a business glossary, GitHub pull request impact analysis, and a self-service layer for business users unfamiliar with dbt’s schema structure.
Why does dbt Catalog sometimes show incomplete or outdated metadata?
Permalink to “Why does dbt Catalog sometimes show incomplete or outdated metadata?”dbt Catalog depends on metadata generated by dbt Cloud runs and related APIs. Some integrations reference a three-month retention window for certain dbt Discovery API data, which can limit how far back metadata can be retrieved. To minimize gaps, ensure dbt jobs run consistently and that documentation artifacts are regenerated as part of your workflow. For governance-grade historical metadata and cross-stack lineage, teams often extend dbt with a dedicated data catalog.
Can dbt Core users access dbt Catalog?
Permalink to “Can dbt Core users access dbt Catalog?”No. dbt Catalog is only available as part of dbt Cloud on Starter, Enterprise, and Enterprise+ plans. If your team uses dbt Core on-premises or self-hosted, you won’t have access to dbt Catalog’s lineage and discovery features. You can still generate static dbt Docs locally, but those lack Catalog’s stateful metadata and performance analysis. Teams in this situation can explore open-source data catalog tools or connect dbt Core directly to Atlan.
How do data catalogs support AI workflows for dbt teams?
Permalink to “How do data catalogs support AI workflows for dbt teams?”Structured metadata in your data catalog provides the trusted context that AI tools need to reason over your dbt models. When dbt metadata is cataloged and governed, AI-assisted documentation, natural language queries, and governed agentic workflows all become more reliable. According to dbt Labs’ 2025 State of Analytics Engineering report, 70% of data practitioners already use AI for analytics code development.
The bottom line on dbt data catalog
Permalink to “The bottom line on dbt data catalog”dbt Catalog has grown significantly. It covers lineage, documentation, and project health in one experience. But for teams that need governance beyond the dbt boundary, a business glossary, or lineage across their full stack, Atlan picks up where dbt Catalog leaves off. Together, they give your analytics engineers and business users a complete picture.
