



















ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) are two methods for data integration. ETL transforms data before loading it into a target system, making it ideal for legacy systems and compliance-heavy industries.
ELT loads raw data first and performs transformations in modern cloud-native environments, optimizing for scalability and real-time analytics. ETL suits batch processing, while ELT excels in handling large-scale, dynamic data.
Watch Context Studio Demo
Understanding their differences helps organizations choose the right method to streamline data workflows, improve performance, and meet business goals efficiently.
The data stack is evolving with the explosion of data, and data lakes are becoming mainstream. However, you have to integrate data before using it for analytics and reporting. So, which data integration process is ideal — ETL or ELT? The answer: It depends.
ETL (Extract, Transform, Load) transforms data before storing it in a warehouse, whereas ELT (Extract, Load, Transform) loads data into a lake before modifying and organizing it, depending on specific use cases.
This article will dive deeper into these data integration processes and explore their fundamental differences, pros, and cons, and use cases.
What is ETL (Extract, Transform, Load)?
Permalink to “What is ETL (Extract, Transform, Load)?”ETL is a data integration process that:
- Extracts raw data from various sources and formats
- Transforms that data using a secondary processing server
- Loads the transformed, structured data into a target database — usually a data warehouse
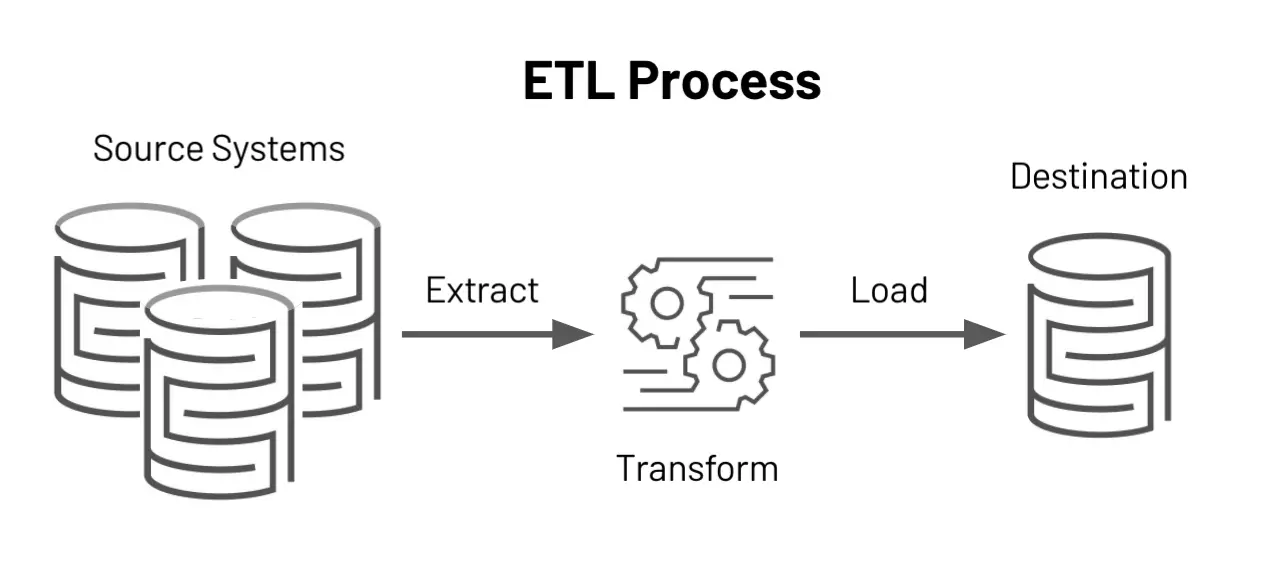
What does the ETL process look like? Source: Databricks
An example of ETL is loading into the Online Analytical Processing (OLAP) data warehouse. These warehouses only accept relational, SQL-based data structures. So, you must transform data before loading it into the OLAP warehouse. In some cases, you may have to use data mapping to combine multiple data sources.
What is ELT (Extract, Load, Transform)?
Permalink to “What is ELT (Extract, Load, Transform)?”Unlike ETL, you don’t have to move data to a processing server for transformation until you load it into a warehouse.
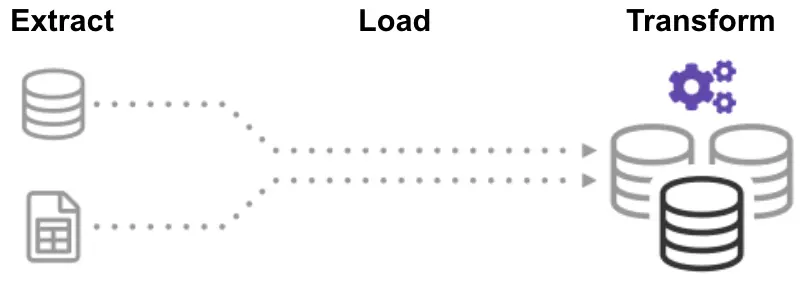
What does the ELT process look like? Source: Panoply
The data cleansing and transformation processes occur inside the data lake when using ELT.
ELT is used in conjunction with data lakes, which can accept both structured and unstructured data and don’t require transformation to organize or structure data before storage.
However, it’s important to note that you must transform data before using it for analytics and reporting.
Also, read → Extract, transform, and load (ETL)
ETL vs. ELT: Differences explained
Permalink to “ETL vs. ELT: Differences explained”The history of ETL and ELT
Permalink to “The history of ETL and ELT”The rise of ETL and the Schema-On-Write approach to database architecture
ETL rose to prominence in the 1970s when organizations began using multiple databases to store information — data had to be integrated quickly as the use of these databases continued to grow.
Around the 1980s, we saw the introduction of data warehouses, which provided access to structured data from multiple sources. So, ETL became the standard data integration method.
With ETL, organizations used the Schema-On-Write approach, where:
- You must define your schema — the structure of your database.
- You process and load data into the database using the ETL process.
- You can now read data as per the schema — the structure defined.
While organizations have been using the Schema-On-Write approach for designing their database architectures traditionally, there’s a caveat — you must know how you’re going to use your data before exploring and processing it.
The downsides of the ETL for data integration
As cloud computing rose to prominence, the amount of data generated and available for analytics grew exponentially. As a result, three major drawbacks of the ETL processes became obvious:
- It was becoming increasingly hard to define the structure and use cases of data before transforming it.
- Transforming large volumes of unstructured data (videos, images, sensor data) using traditional data warehouses and ELT processes was painful, time-consuming, and expensive.
- The cost of merging structured and unstructured data and defining new rules through complex engineering processes was no longer feasible.
Moreover, organizations realized that sticking to ETL wasn’t helpful in processing data at scale and in real-time. Tamr puts it best in its 2014 article on the evolution of ETL:
Data is constantly changing, growing, and no one person has the necessary knowledge. Rules don’t scale when linking hundreds or thousands of sources.
The rise of ELT and Schema-On-Read approach to data integration
Eventually, ELT became a necessity. Unlike ETL, ELT uses the Schema-On-Read approach to store data in its raw state. You can define the schema — rules and structure — to model just the data you need whenever you wish to use it.
According to Deloitte:
ELT (instead of ETL) is built to leverage the best features of a cloud data warehouse: elastic scalability as needed, massively parallel processing of many jobs at once, and the ability to spin up and tear down jobs quickly.
So, as the data tech stack evolved to support cloud-based warehouses and data lakes, ELT became a reality.
Today, cloud-native platforms — Microsoft Azure, Amazon Redshift, and Snowflake — have the storage capacity and processing power necessary to support ELT.
Additionally, as per Dataconomy’s Future Trends in ETL blog, Traditional ETL processes often struggle to scale efficiently, leading to performance bottlenecks and resource constraints during peak data loads. Data sources’ increasing diversity and complexity pose challenges in harmonizing and integrating this data within traditional ETL workflows.
Key differences between ETL and ELT
Permalink to “Key differences between ETL and ELT”The primary differences between ETL and ELT are:
- ETL uses the Schema-On-Write approach to transform data before it enters the warehouse. Meanwhile, ELT uses the Schema-On-Read approach to transform data within the data warehouse or lake.
- ETL is used for smaller data sets, whereas ELT is used for larger volumes of data, both structured and unstructured.
Another crucial aspect to note is the way both approaches were developed. ETL was built with IT in mind, whereas ELT is built for the average data consumer.
ETL requires engineers to define the rules for data processing and storage, then handle the entire integration process before data becomes useful. When there are large volumes of data pouring in every second, this approach causes engineering bottlenecks, and data consumers have to wait weeks, even months, before they get the data they need for decision-making.
On the other hand, the introduction of ELT has meant that data scientists and business analysts can get involved with data at an earlier stage in the pipeline and remove some of the bottlenecks that arose with ETL.
So, the average data consumer has access to relevant data assets and can use pre-defined and built-in workflows to transform the raw data and extract value from it. In addition, the rise of modern, self-service data platforms enables business users to handle data integration without relying on IT.
To summarize, here’s a table outlining the differences between ETL vs. ELT across several categories:
| Category | ETL | ELT |
|---|---|---|
| Acronym Meaning | Extract, Transform, Load | Extract, Load, Transform |
| Definition | Extracts raw data from sources, transforms it using a secondary processing server, and then loads it into a target database. | Extracts raw data and loads it directly into a target data warehouse or lake before it gets processed. |
| Speed | Data is transformed before loading. So, the process is longer and can become complex. | Since data can be loaded directly and then transformed, this is a faster process. |
| Maturity | A well-established process that has been around for 20+ years with proper documentation, protocols, and tools. | A newer data pipeline model with less documentation and tooling available. |
| Costs | Expensive to extract insights from raw data at scale | Leverages cloud-based systems to reduce costs |
| Data Volume | Suited for smaller data sets with greater complexity such as marketing data integrations | Suited for larger data sets where speed is required such as stock market data |
| Data Output | Structured | Structured or unstructured |
| Data Lake Support | Isn’t compatible with data lakes | Offers support for data lakes |
ETL vs. ELT: Pros and cons
Permalink to “ETL vs. ELT: Pros and cons”There are pros and cons of using ETL and ELT depending on the situation. Let’s break them down.
Advantages of ETL
Permalink to “Advantages of ETL”- Final data analysis is more efficient and reliable as data is organized using a set of rules and definitions before storage.
- ETL is more reliable when dealing with sensitive data requiring strict compliance with regulations such as GDPR and HIPAA. For example, PII data must be encrypted or anonymized for privacy. ETL lets you define the rules of data storage, security, and privacy so that it gets stored in compliance with regulations.
- ETL has existed for a long time, making it easier to find tools and platforms that support it and engineers familiar with how it works.
Disadvantages of ETL
Permalink to “Disadvantages of ETL”- Data may not be in the desired format for analysis after it is loaded.
- Data analysts and engineers may need to spend time editing improperly formatted data before loading.
- ETL can form a bottleneck when there’s lots of data to be processed every second due to the overreliance on IT, as mentioned earlier.
Advantages of ELT
Permalink to “Advantages of ELT”- ELT is more flexible and efficient at managing large data sets. This enables real-time data analysis and speeds up insightful decision-making.
- ELT leverages and works well with cloud-native tools, which are less costly and require less maintenance.
- ELT is built for data consumers and speeds up analytics. With ETL, sometimes, data teams have to wait weeks and probably months for some of their data sets, and that data becomes redundant by then.
Disadvantages of ELT
Permalink to “Disadvantages of ELT”- Using ELT to handle sensitive data can cause you to violate compliance standards if you aren’t careful.
- ELT emerged more recently, meaning there is less documentation, tooling, and experienced professionals available to set it up.
ETL vs. ELT: Use cases
Permalink to “ETL vs. ELT: Use cases”While ETL and ELT are both valuable, there are particular use cases when each may be a better fit.
Marketing Data Integration: ETL is used to collect, prep, and centralize marketing data from multiple sources like e-commerce platforms, mobile applications, social media platforms, So, business users can leverage it for delivering more personalized user experience and messaging.
Database Migration: Organizations can use ETL to move data from on-premises locations to a cloud data warehouse. This is particularly useful when organizations are going through mergers and have to club their siloed data to form a central repository.
Data Replication: Data can be moved from multiple sources and copied to a cloud data warehouse.
ELT use cases
Permalink to “ELT use cases”Instant-access data organizations: Stock exchanges, wholesale distributors, and other organizations that need real-time access to current data for business intelligence can benefit from ELT.
High-volume data organizations: Companies that process large volumes of raw data, such as meteorological centers and astrology labs, can use ELT.
Also, read → Data Integration vs ETL
How organizations making the most out of their data using Atlan
Permalink to “How organizations making the most out of their data using Atlan”The recently published Forrester Wave report compared all the major enterprise data catalogs and positioned Atlan as the market leader ahead of all others. The comparison was based on 24 different aspects of cataloging, broadly across the following three criteria:
- Automatic cataloging of the entire technology, data, and AI ecosystem
- Enabling the data ecosystem AI and automation first
- Prioritizing data democratization and self-service
These criteria made Atlan the ideal choice for a major audio content platform, where the data ecosystem was centered around Snowflake. The platform sought a “one-stop shop for governance and discovery,” and Atlan played a crucial role in ensuring their data was “understandable, reliable, high-quality, and discoverable.”
For another organization, Aliaxis, which also uses Snowflake as their core data platform, Atlan served as “a bridge” between various tools and technologies across the data ecosystem. With its organization-wide business glossary, Atlan became the go-to platform for finding, accessing, and using data. It also significantly reduced the time spent by data engineers and analysts on pipeline debugging and troubleshooting.
A key goal of Atlan is to help organizations maximize the use of their data for AI use cases. As generative AI capabilities have advanced in recent years, organizations can now do more with both structured and unstructured data—provided it is discoverable and trustworthy, or in other words, AI-ready.
Tide’s Story of GDPR Compliance: Embedding Privacy into Automated Processes
Permalink to “Tide’s Story of GDPR Compliance: Embedding Privacy into Automated Processes”- Tide, a UK-based digital bank with nearly 500,000 small business customers, sought to improve their compliance with GDPR’s Right to Erasure, commonly known as the “Right to be forgotten”.
- After adopting Atlan as their metadata platform, Tide’s data and legal teams collaborated to define personally identifiable information in order to propagate those definitions and tags across their data estate.
- Tide used Atlan Playbooks (rule-based bulk automations) to automatically identify, tag, and secure personal data, turning a 50-day manual process into mere hours of work.
Book your personalized demo today to find out how Atlan can help your organization in establishing and scaling data governance programs.
Finishing up: Knowing when to use ETL vs. ELT
Permalink to “Finishing up: Knowing when to use ETL vs. ELT”When data pipeline methods first came onto the scene, the people that handled data were part of the IT department. However, in today’s digital world, teams are much more diverse with less technical personnel involved in data analysis and needed to gather insights. So, pick a method that works best for your team and available resources, data tech stack, and use cases.
FAQs about ETL vs. ELT
Permalink to “FAQs about ETL vs. ELT”1. What is the difference between ETL and ELT?
Permalink to “1. What is the difference between ETL and ELT?”ETL (Extract, Transform, Load) transforms data before loading it into a destination, while ELT (Extract, Load, Transform) loads data into a storage system first and performs transformations afterward. ETL is ideal for legacy systems and batch processing, whereas ELT leverages modern cloud-based systems for real-time analytics and scalability.
2. When should you use ETL instead of ELT?
Permalink to “2. When should you use ETL instead of ELT?”ETL is preferred when working with structured data in compliance-heavy industries or when using on-premises systems with limited processing power. It ensures that only cleaned and transformed data enters the storage, which is crucial for systems with strict data governance requirements.
3. What are the advantages of ELT in modern data environments?
Permalink to “3. What are the advantages of ELT in modern data environments?”ELT is highly scalable and ideal for cloud-native environments. It allows for faster data loading and real-time transformations by utilizing the computational power of modern data warehouses like Snowflake or BigQuery. This flexibility makes it suitable for big data and agile analytics needs.
4. How do ETL and ELT impact data warehousing?
Permalink to “4. How do ETL and ELT impact data warehousing?”ETL is more suited for traditional data warehousing, where pre-transformed data ensures data integrity and compliance. ELT, on the other hand, optimizes for cloud data warehouses by performing transformations within the storage layer, improving performance and reducing data latency.
5. What are the key considerations for transitioning from ETL to ELT?
Permalink to “5. What are the key considerations for transitioning from ETL to ELT?”Transitioning to ELT involves ensuring your infrastructure supports cloud-native data processing. You’ll need a modern data warehouse, tools for orchestrating post-load transformations, and strategies for managing semi-structured or unstructured data efficiently. Proper governance and performance optimization are also essential.
