



















Understand the DataOps principles, framework and learn how to implement DataOps within your organization.
Let’s start with a simple definition of DataOps (aka data operations).
DataOps is a data management framework that borrows from the agile methodology, lean manufacturing and DevOps to democratize data, build trust and improve team collaboration.
What is DataOps?
Permalink to “What is DataOps?”Sounds quite straightforward, right? If only it were that easy to implement! 🥺
We’re talking messy data like audio files, emails, photos, or satellite imagery to more neat and clean data like phone numbers, customer names, addresses and zip codes.
Let’s quickly recap why we need DataOps in the first place.
Why DataOps?
Permalink to “Why DataOps?”If you’re a data team, then this must be a very familiar scenario.
Diverse teams and technologies within organizations.
Permalink to “Diverse teams and technologies within organizations.”Different teams within your organization use a bunch of different tools and technologies to do their jobs. Customer support uses Intercom or Zendesk to make sure customers are engaged and happy.
The sales team uses Salesforce to bring in new business. Whereas Marketing uses HubSpot, Google Analytics and a fleet of social media platforms to build marketing campaigns that attract new customers.
Oh, and the product team … we haven’t forgotten about you! You use Typeform or SurveyMonkey to run extensive surveys for research and product development.
Ah, and then there’s the data team. Data scientists use external sources of data such as satellite data or census data to spot business opportunities. Data engineers build and manage pipelines that orchestrate the big data pouring into your systems every second.
The DevOps team manages the data lake and/or a data warehouse that stores all that data—support tickets, demo requests, online browsing activity. While IT sets up access protocols to control data access, quality, integrity and security.
Now all that looks seamless on paper.
However, we all know that in practice, this scenario is messy, chaotic and often, not something under anyone’s control.
From data silos and quality issues to collaboration overhead and excruciatingly slow deliveries—the challenges are too many and too complex… 😰
…making conversations like these quite common within enterprises:
Data teams in chaos
Permalink to “Data teams in chaos”“I am frustrated. 😩 The business keeps demanding insane outcomes and doesn’t help at all in fixing foundational data quality. We have made so much progress but no one in business even understands.”
- Larry, the data lake owner
" I made a request for the data 14 days ago. 😕 Any ETA when you’ll share it?"
- Sam, the business manager
“What does variable column_xy881 stand for in the data set sales_mm_blr_2919.csv?”
- Dalia, the data scientist
Is there a way to bring order to this chaos… be better, faster and more agile with data-driven decisions?
DataOps might just be the answer.
What is DataOps?
Permalink to “What is DataOps?”Like we mentioned earlier, it’s a data management framework.

DataOps definition
DataOps principles
Permalink to “DataOps principles”Remember that we mentioned it borrows from the principles of Agile, lean manufacturing, and DataOps?
DataOps principles help data teams deliver, deploy and make decisions faster. And that too without compromising the quality or integrity of data.
That means making data-driven changes and decisions at the speed of business. ⚡️
Now how can one implement DataOps… is there a framework to follow?
DataOps framework
Permalink to “DataOps framework”
What is DataOps?
Eckerson even provides an illustration of this environment.
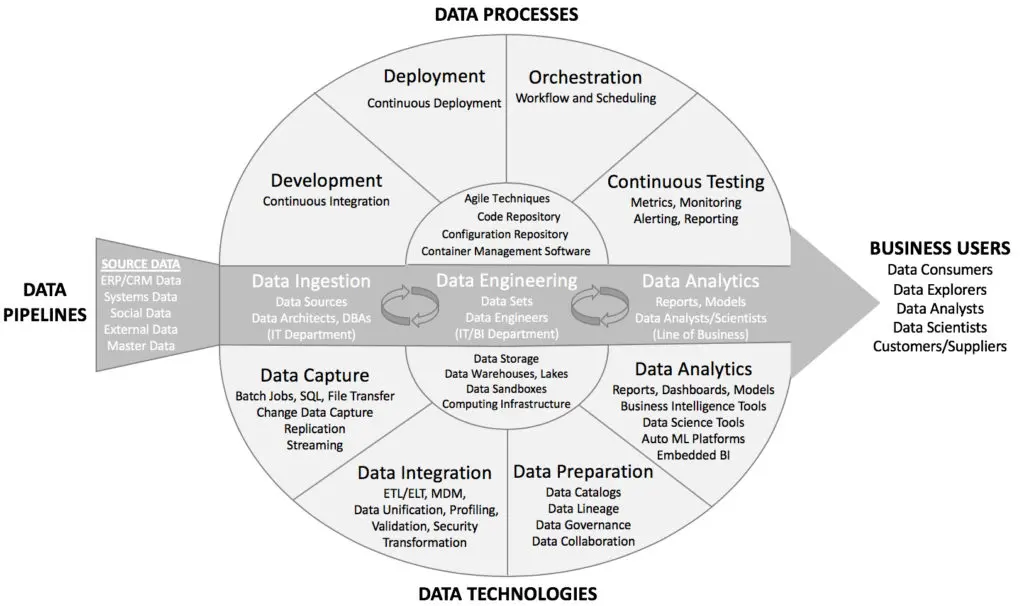
DataOps Components
TMI? 😅
Let’s dissect this framework.
Data pipelines move data from one place to another, transforming it for specific functions—reporting, analytics, BI and so on.
There are several technologies—data integration, preparation, analytics—and processes—development, deployment, orchestration—that use these pipelines.
While everyone wants and uses some form of technology for analytics (aka where the $$$ is), not many focus on the processes.
And that’s the reason why data lives in silos or why collaboration is a chaos.
Orchestration—the key to bringing order to your data chaos
Permalink to “Orchestration—the key to bringing order to your data chaos”You might be scratching your head thinking—why just orchestration? 🤔
Because DevOps principles and practices take care of development, deployment and continuous testing. That leaves us with orchestration—moving, processing, transforming data—the process that’s at the heart of DataOps.
Alright, so is there a perfect solution for data orchestration?
An orchestration layer for your data stack
Permalink to “An orchestration layer for your data stack”There are plenty of tools available, some of which are open-source (like Airflow). But, they don’t help get rid of silos or completely remove dependencies.
That’s because orchestration is traditionally a task (a Herculean one) for engineering and IT, often taking months to deliver results. The times we live in, we can’t afford to wait THAT long!
What would come in handy is if everybody’s empowered to do data orchestration—with a canvas for data projects.
Imagine a drag-n-drop canvas that:1. Let’s you build automated workflows 2. Integrates with your favorite data tools and technologies (Python, R, Jupyter, Tableau and more) 3. Requires little or no coding at all
With such an intuitive canvas, you’ll empower your team to automate data-driven business processes—reporting, AI/ML (machine learning) and more.
Empowered data consumers + orchestration = faster delivery, zero dependencies, no human grunt work 🚀
A collaboration layer for your data stack
Permalink to “A collaboration layer for your data stack”Ah, but well-oiled pipelines alone won’t be enough … you also need to build a winning data culture to improve collaboration—bring all the diverse humans of data on the same page.
Now you could use email, Slack and other messaging apps to improve communication within teams. Or, you could get your hands on something better and simpler.
Imagine a data workspace where data has a profile—complete with metadata information, data dictionary, business glossary, READMEs and more.
You’ll never have to deal with the loss of human tribal knowledge or lack of business context for your data. 🙌
Final Word
Permalink to “Final Word”DataOps as a concept isn’t new. And implementing the DataOps principles or DataOps framework isn’t a revolutionary practice. There are several technologies available to help you out.
However, your goal isn’t to add yet another piece of tech to your already crowded data stack—you’ll only add on to the silos.
Your mission is to make things easier for your data team by:1. Bringing visibility and transparency to your data stack and processes 2. Improving data quality 3. Building trust in your data 4. Reducing the time it takes to make data-driven decisions
All that while keeping the bad data in your systems to a minimum and complying with data regulations and policies (i.e. data governance).
We experimented for two years, across 200 data projects, to create our own view of what makes data teams successful. Happy to share it with you.
Read our DataOps Culture Code.
