



















Databook explained
Permalink to “Databook explained”Databook is Uber’s in-house metadata management platform that democratizes data discovery and exploration at scale. Databook is to Uber, what Amundsen is to Lyft, DataHub is to LinkedIn, and Metacat is to Netflix.
Is Open Source really free? Estimate the cost of deploying an open-source data catalog 👉 Download Free Calculator
In 2010, Uber revolutionized the transportation industry, currently operating in more than 10,000 cities with millions of users worldwide. Since its inception, Uber has diversified its business to quite an extent. It connects passengers to drivers, foodies to restaurants, carriers to shippers, and more. The organization processes vast amounts of daily real-time data produced against user ride requests, payments, restaurant orders, shipping details, etc. The Databook tracks all of these different data sources and maintains a data catalog.
Data catalogs are going through a paradigm shift. Here’s all you need to know about a 3rd Generation Data Catalog
Learn MoreDatabook was built to catalog the metadata linked with Uber’s datasets, dashboards, location data, analytics, and marketing metrics. Uber aimed to facilitate employees exploring and eventually converting the petabytes of real-time operational data into intelligence using the contextual information available in the data catalog.
Evolution of Databook (2016-2020)
Permalink to “Evolution of Databook (2016-2020)”The first Databook was launched by Uber in 2016 when the overall data infrastructure was simple and relatively much less distributed. Before that, Uber cataloged its datasets and tables using static HTML pages, maintained and updated manually. As the company grew, Uber Databook replaced the static HTML pages, which worked reasonably well for some time.
Uber then established new business chains to expand its venture, including Uber Eats, Uber Elevate, Uber Freight, and Bikes. This expansion resulted in exponential data growth and deemed the development of a more advanced data catalog software necessary.
Employees at Uber started classifying the data in more detail. They collected details about the datasets, their owners, how data is generated, which business metrics were derived from the datasets, which dashboards are built, information about data storage pipelines, and descriptions of various table columns.
In 2017, Uber redesigned Databook (Databook 2.0) from the ground up to accommodate these changes as it complimented the decision-making process and helped deduce meaningful business insights. The updated Databook came with a responsive UI and improved functionalities for new data requirements.
Uber added more information about their data collection strategy to the Databook. They introduced Querybuilder, a front-end functionality to search and discover Uber’s databases, and Dashbuilder, which is an advanced metadata visualization tool, that helps users learn and better understand the data relationships.
Uber Databook Architecture
Permalink to “Uber Databook Architecture”The initial Databook architecture was focused on a basic system for searching data sets and surfacing descriptions and owners, which was nowhere near sufficient when their data landscape started burgeoning in both volume and complexity.
The section discusses the principles that helped redesign, reevaluate, and rebuild the Databook architecture. Based on these principles, we’ll discuss the various architectural components of Databook 2.0.
Principles of Databook Architecture
Permalink to “Principles of Databook Architecture”Databook design principles are essential guidelines that helped build a solid foundation for the restructuring strategy. These include:
- The Meaning of Metadata Is Important
- Truly Extensible Data Model
- Centralized Versus Decentralized Metadata System
- Focus on the User Experience
- Importance of Relationships Between Data Entities
- The Meaning of Metadata Is Important
With the increase of data entities and metadata sources, data documentation became inconsistent. For better metadata management, a schema generation tool called Dragon was developed that assists in structuring and maintaining consistent metadata vocabulary.
- Truly Extensible Data Model
The first Databook kept metadata restricted to specific datasets, disregarding non-dataset sources like dashboards and business metrics. Adding diverse data entries in one model compromised its clarity and understandability. Uber built a flexible and extensible data model to insert the data entities with disparate metadata instead of fitting them into a pre-defined data model.
- Centralized Versus Decentralized Metadata System
As the metadata sources increased, replicating metadata systems with similar use cases was unfavorable. Uber developed a centralized system for handling all metadata sources and data entities.
- Focus on the User Experience
Uber encouraged its developers, analysts, and Databook end-users to provide feedback on improving the Databook features. Based on the user experience, Uber streamlined its metadata ingestion pipeline and improved the Databook UI to allow better metadata discovery.
- Importance of Relationships Between Data Entities
The data in the Uber application flows in from different routes like Kafka to Hive. Adding more data entities to the system increased the complexity of these routes. Uber used a Graph data structure to represent the relationship between these complex data entities accurately.
Uber Databook Features
Permalink to “Uber Databook Features”From the five principles discussed above, the Databook 2.0 architecture derived the following features:
- Standard vocabulary for metadata association
- Extendable data model to accommodate disparate metadata and its respective relationships
- Improved user experience via Databook UI and APIs
Components of Uber Databook
Permalink to “Components of Uber Databook”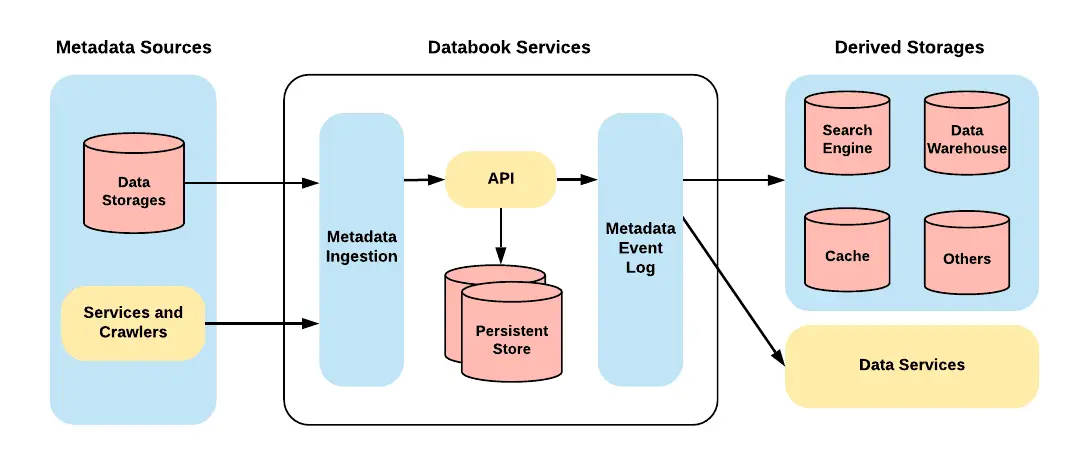
Uber Databook 2.0 Architecture. Image by Lyft Engineering
Uber receives data from various input sources, processed and stored in multiple data repositories. The Databook 2.0 added various metadata sources, storage units, ingestion mechanisms, and event logs to manage the massive scale of incoming data and fuel further Uber data services. Following are the components:
- Metadata Sources
- Metadata Ingestion
- Persistent Storage
- Metadata Event Log
- Derived Storages
A detailed description of each of the Databook components is given below:
- Metadata Sources
Uber operates with data entities stored in various storage units like Hive, Cassandra, MySQL, Vertica, etc. Databook has a flexible framework to support numerous use cases to adjust data entities from data storage systems or web crawlers that feed input. Databook uses a uniform entry process and standardized APIs to ensure scalability.
- Metadata Ingestion
Different team members need to perform various tasks by accessing metadata sources. The metadata ingestion process helps organize the data for members and updates the event log with all details and history of the changes.
- Persistent Storage
MySQL is used to preserve the entire track of data and the associated relationships. It provides flexibility, accessibility, and extensibility to the Databook architecture. ElasticSearch is also used to improve the indexing and speed up metadata search.
- Metadata Event Log
After metadata ingestion, the transformation details are listed in Kafka’s Event log. This data assists in auditing, rebuilding repositories, and triggering various tasks. The event log keeps track of the Databook activities and updates the changes in real-time.
- Derived Storages
Derived storage assists various use cases and requirements using the Metadata Event Log. Uber captures essential metadata maintained by different storage units as a single storage repository cannot manage diverse patterns and data demands.
Databook Use Cases
Permalink to “Databook Use Cases”With a redesigned architecture, Uber improved and enabled the following uses cases of Databook:
- Discover
Uber users frequently searched Databook for data entities related to their workplaces or other popular data entries of the organization. Uber introduced organized data entities representation to improve the Databook interface. After tracking the activities and preferences of the users, Uber added a feature to recommend entities of their interests. The search engine was optimized to intelligently interpret the keywords and produce relevant results.
- Understand
After guiding the users to search, the Uber team wanted to move forward and help them understand intricate details about the data. The Databook architecture was redesigned by adding more signals about the data entities like usage analysis, data quality, and privacy metrics.
The Databook web UI used traffic-light-indicator representation to display the data quality or status of the assets. The traffic light signal colors help notify the users about the availability of assets or the presence of an anomaly.
- Manage
The expansion of the data model with different data entities and metadata sources overloaded the system. Uber wanted to streamline the communication channel to contact the data providers directly, ask queries and give feedback.
Uber established an interface that handled all data entities on a single page where the users could post their questions and report their problems. A knowledge-based representation was provided to the Databook users instead of a wiki-based model to manage data entities. The interface tracks the issues at the back-end and routes the inquiries to the members available.
Is Uber Databook Open Source?
Permalink to “Is Uber Databook Open Source?”Uber Databook is NOT an open-source metadata cataloging tool. The Databook is Uber’s in-house platform, and its code repository is not shared publicly on GitHub.
However, the Databook architectural design and its complete restructuring journey details are publicly available. It serves as a guide for organizations interested in building open data catalog software.
Conclusion
Permalink to “Conclusion”This article has discussed Databook, a metadata catalog built by Uber to meet their ever-growing data discovery, exploration, and management needs. We have covered the components of Databook, the design principles, and essential features that give you an insight into how Databook works.
Interested in understanding how other big tech companies managed their evolving data requirements? Dive into this list of top open-source data catalog software.
Also, if you are looking to deploy a data catalog for your own team, you might want to check out Atlan - a third-generation data catalog that’s a leap from legacy software and built on the best of open source.
