



















What is Amundsen Data Catalog?
Permalink to “What is Amundsen Data Catalog?”Amundsen is a data discovery platform and metadata engine that was developed at Lyft to address the common pain points faced by their data scientists, engineers, and researchers in their typical workflows.
Homegrown by the Lyft engineering team, Amundsen was named after Norwegian explorer Roald Amundsen, who’s most famous for leading the first successful expedition to the South Pole.
Amundsen has improved the productivity of data scientists, analysts, and researchers at Lyft by ~20%
\[Download ebook\] A Guide to Building a Business Case for a Data Catalog
Download EbookWhy did Lyft build Amundsen?
Permalink to “Why did Lyft build Amundsen?”Lyft reported an active rider base of 13.49 million in the first quarter of 2021. Now, imagine this number, in turn, generating a tremendous amount of data to be stored, processed, and analyzed, and also the huge number of people who might be using this data daily to make informed decisions.
At a fundamentally modern data-driven company like Lyft, every interaction is powered by data, and it’s impossible to scale sustainably if the data teams are not empowered to productively and effectively use this data.
Lyft recognized this challenge and developed Amundsen, which they introduced in April 2019 as a solution to their data discovery woes.

Amundsen was developed to minimize time spent in discovering and trusting data. Source: Lyft Engineering
Lyft created Amundsen to be able to
- Capture metadata from all their different data sources
- Generate visibility (via metadata) on how data has evolved through its lifecycle
- Share this metadata with users by a frontend to enable them to discover, trust and use the data.
Is Amundsen data catalog open source?
Permalink to “Is Amundsen data catalog open source?”Amundsen was open-sourced in October 2019, a year following its launching in production at Lyft & is licensed under the Apache License, Version 2.0. A copy of the license can be found here. Here’s a roundup of the permissions, limitations, and conditions that govern the license.

Source: Amundsen GitHub
Amundsen was donated to Linux Foundation AI in July 2020.
Data Catalog 3.0: The Modern Data Stack, DataOps, and Active Metadata
Download EbookHow does the Amundsen data catalog work?
Permalink to “How does the Amundsen data catalog work?”Amundsen data catalog primarily works towards enabling users to discover, trust and understand their data. The various features of Amundsen all work together to achieve the same. Following are Amundsen’s main capabilities:
- Easy discovery of trusted data
- Automated & curated metadata
- Ability to share context with coworkers
- Learn and understand from data usage
Easy discovery of trusted data
Permalink to “Easy discovery of trusted data”Amundsen helps find data within an organization by a simple text search. The search results go to the extent of showing in-line metadata - that includes a description of data and also the last date when it was updated. The page-rank-inspired algorithm returns with popularity ranking and also recommendations - highly queried tables are bumped higher for consideration, while least used tables are populated later in the results.

Google like search to discover the right data across all your data sources. Source: Lyft Engineering
Automated and curated metadata
Permalink to “Automated and curated metadata”When a data asset is clicked on, users are shown its detailed description and its behaviour. Detail description includes manually curated information by users. Information about behaviour of the data is generated by grazing through audit logs. By design, users are encouraged to use column level data based on popularity. Users also have visibility on popular users and general profile of the data.

Amundsen's data dictionary adds rich context to every data asset at column level. Source: Lyft Engineering
Demo: Get access to an Amundsen sandbox instance populated with sample data
Watch DemoAbility to share context with coworkers
Permalink to “Ability to share context with coworkers”One can update descriptions to data assets, thus reducing back and forth between co-workers looking for more context in a particular data asset - for example, updating tables and columns with descriptions may give a data user necessary information about which table is the best fit to a particular query and which particular query in that table is of particular interest.
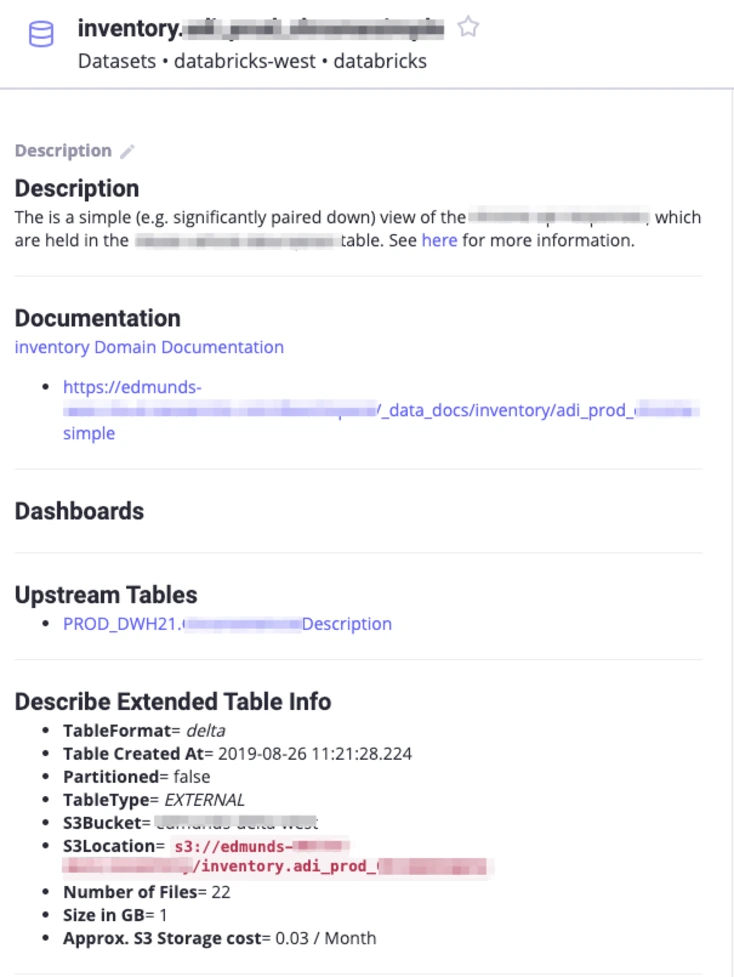
Manually fed descriptions for better context to viewer. Source: Amundsen GitHub
Learn and understand from data usage
Permalink to “Learn and understand from data usage”Users can see which data assets get frequently used, owned, or bookmarked. One can even understand the most common queries for a table by seeing dashboards built on a given table. This is what classifies as behaviour metadata - and is automatically curated.

Visibility of relationship between users and resources. Source: Lyft Engineering
The Lyft Amundsen Architecture
Permalink to “The Lyft Amundsen Architecture”Amundsen by Lyft consists of five major components and follows a micro-service architecture:
- Metadata Service: Able to handle requests from both frontend service and microservices
- Search Service: Backed by Elastic search
- Frontend Service: Hosts the web application
- Databuilder: Ingestion framework which extracts metadata from various sources
- Common Components: Library repository that holds common codes among microservices
Metadata Service
Permalink to “Metadata Service”Able to handle requests from both frontend service and microservices. Essentially, the metadata is exposed via the front-end service to end-users and is also used for other services at Lyft. It is interesting to note that metadata entities are currently modeled as graphs on Amundsen which makes it easier to extend the model when more entities are produced.
Search Service
Permalink to “Search Service”Backed by Elastic search - the search service makes provision for an API to index resources into the search engine, and serve search queries from end-users via the front-end service. Currently, Amundsen supports the following kind of searches:
- Normal search: Search specifying particular term and resource term
- Category search: Filtered resources if search term matches a metadata category, relevancy is considered while serving results
- Wildcard search: Users can do a wildcard search over different resources
Frontend Service
Permalink to “Frontend Service”Hosts the web application. It consists of two distinct parts:
- A React Application for composing the user interface
- A Flask server acting as an intermediary for metadata or search service requests
Databuilder
Permalink to “Databuilder”The ETL Ingestion framework extracts metadata from various sources. It is said to be highly inspired by Apache Goblin. Each component of the databuilder is highly modularized. Components include:
- Extractor
- Transformer
- Loader
- Publisher (optional)
Common Components
Permalink to “Common Components”Library repository which holds common codes for microservices at Amundsen.

Microservices architecture of Amundsen. Source: Lyft Engineering
Democratizing Data Discovery at Lyft
Permalink to “Democratizing Data Discovery at Lyft”Amundsen is used by 750 data users at Lyft.
Data teams are diverse. Data engineers, data scientists, analysts, product managers, and executives - are all looking for data to process and make informed decisions. True democratization is possible when everyone looking for data resources knows exactly what data is available within the system & how they can use it, but that may also pose challenges with respect to data privacy & security. Amundsen seeks to walk the balance between democratization and security by classifying metadata into two groups:
Fundamental metadata
Permalink to “Fundamental metadata”Fundamental metadata like name and description of table and fields, owners, last updated, etc. are visible to all. This enables users to find its existence and also to understand if it fits their query.
Richer metadata
Permalink to “Richer metadata”Richer metadata like column stats, preview, etc. is only available to users with access to data. One can also request access to richer metadata if they are convinced that it’s the right fit for them.
Lyft Amundsen Key Links
Permalink to “Lyft Amundsen Key Links”Experience Amundsen hands-on: Access a sandbox environment loaded with sample data
Mail Lists:
Resources to get you started on Amundsen:
Permalink to “Resources to get you started on Amundsen:”- Amundsen demo: Take a test drive and get a feel for how the Amundsen data catalog works. Get access to a sandbox instance populated with sample data.
- Amundsen setup: We will guide you through the steps required to configure and install Amundsen.
- A step-by-step walk-through of setting up Amundsen data lineage with dbt
What’s the difference: Comparing open-source data discovery tools
Permalink to “What’s the difference: Comparing open-source data discovery tools”- Learn more about how Amundsen compares with other open source data catalog and metadata tools:
- Lyft Amundsen Vs. Linkedin DataHub: A deep dive into how Amundsen and DataHub compare in terms of architecture, metadata ingestion, ease of deployment, and core data discovery features.
- Lyft Amundsen Vs. Apache Atlas: Read more about how Amundsen and Apache Atlas compare and contrast in data discovery, data catalog, and data lineage features.
- Understanding AWS Glue data catalog: Architecture, components, and crawlers
Learn more about data catalogs:
Permalink to “Learn more about data catalogs:”- Evaluating a data catalog? Here are the 5 essential features to look for in a modern data catalog
- Data Catalog: The Must-Have Tool for Data Leaders in 2023
- What are the benefits of a data catalog? 5 key reasons why you need one
- Data catalogs are going through a paradigm shift! Here is everything you need to know about the Third-Generation Data Catalog.
- Learn more about Atlan: The pioneering third-generation data catalog for modern data teams.
Amundsen is widely adopted within Lyft and enjoys a cohesive community of individuals and organizations who have extended and used it. However like any other open-source tool - it’s made by engineers and for engineers, thus quite technical to set up.
If you are a data consumer or producer and are looking to champion your organization to optimally utilize the value of a modern data stack - while weighing your build vs buy options, it’s worth taking a look at off-the-shelf alternatives like Atlan — Home to the modern data teams.
