



















Apache Atlas was one of the first open-source software to solve problems related to data management, discovery, and governance. Amundsen is known for its involved and buzzing community - with over 37 organizations officially using it and 100+ contributors.
Cloudera incubated Apache Atlas and engineers from big tech companies such as Merck, SAS, Aetna, and Target worked to build a product that gelled well with the Hadoop ecosystem.
Amundsen, Lyft’s data discovery and metadata platform was announced in April 2019 and open-sourced later in the same year.
Amundsen boosted the productivity of data practitioners at Lyft by 20%. For Cloudera and other enterprises using Hadoop, Apache Atlas was crucial to exchange metadata and model new business processes and data assets quickly.
Amundsen vs. Atlas: Key factors of comparison
- What are the differences in the underlying architecture?
- How does metadata ingestion work in Amundsen and Atlas?
- Assessing the data discovery, lineage, and governance features.
- How do the deployment, authentication, and authorization compare?
- What are the USPs of Amundsen and Atlas and how does the future product roadmap looks for both these data catalog tools?
Amundsen Vs Atlas: Comparison of the underlying architecture
Permalink to “Amundsen Vs Atlas: Comparison of the underlying architecture”Amundsen and Apache Atlas are metadata search and discovery tools built using similar components.
While Amundsen uses neo4j for its database metadata, Apache Atlas relies on JanusGraph. Also, Amundsen uses Elasticsearch, whereas Apache Atlas uses Solr to facilitate metadata search. Both also use REST API for support communication.
However, both metadata tools adopt different approaches to metadata ingestion.
How does metadata ingestion work in Amundsen?
Amundsen’s Databuilder supports a variety of databases to store metadata and integrates with Apache Atlas to handle the backend. For more details, check out this article comparing Amundsen and DataHub.
How is metadata ingestion in Apache Atlas different from Amundsen?
Apache Atlas uses hooks to ingest data. A hook registers to listen to any metadata updates and CRUD operations at the source and then, publishes changes using Kafka messages.
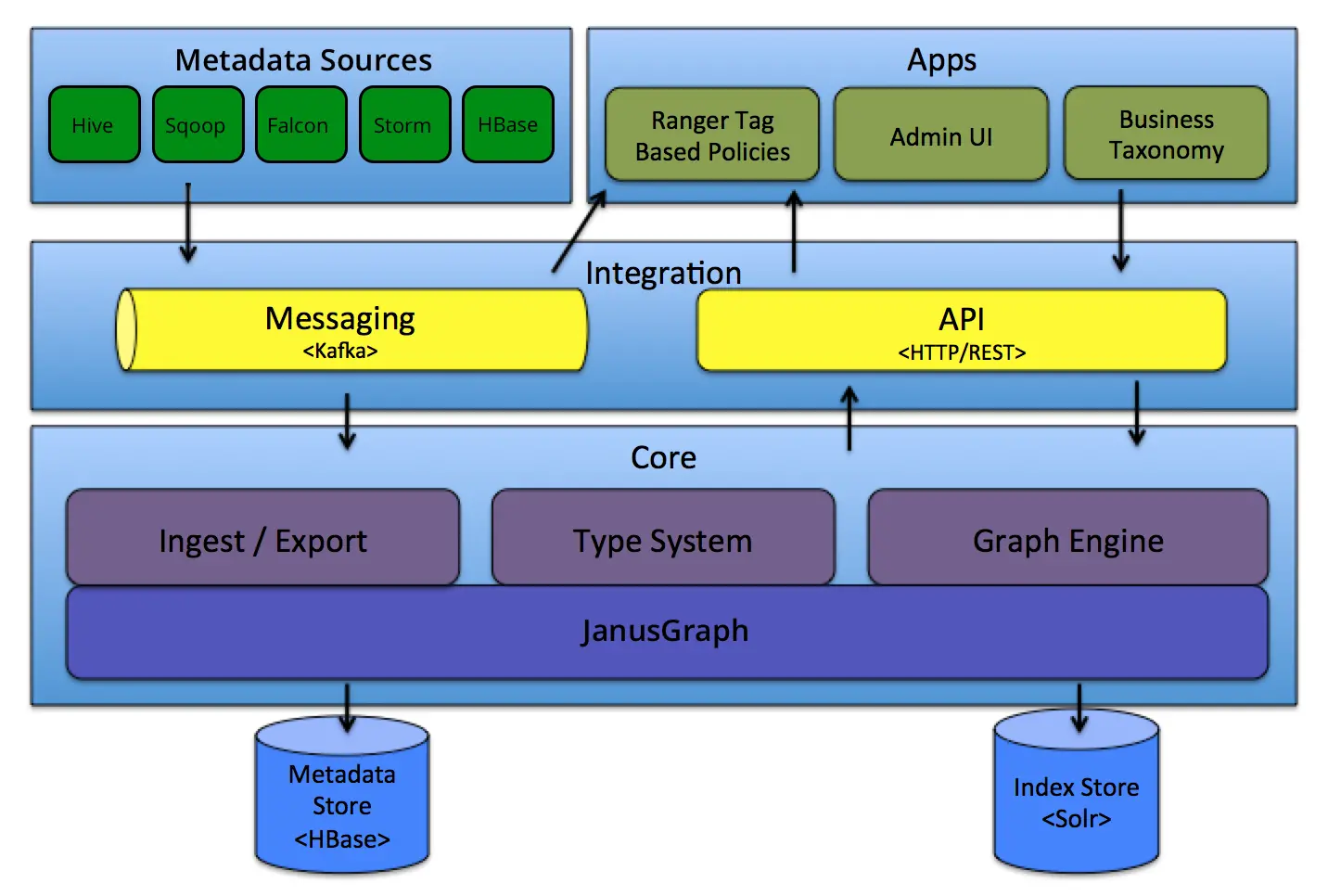
Apache Atlas metadata architecture. Source: Apache Atlas
Apache Atlas relies on out-of-the-box integration with metadata sources from the Hadoop ecosystem projects like Hive, Sqoop, Storm, and so on. However, this doesn’t limit you to using Apache Atlas as you can connect any of your sources to a Hive metastore and use that to ingest metadata into Apache Atlas.
After all, Hive is the standard for metadata storage. It powers AWS Glue Catalog, Google Cloud Hive, Extended Hive Metastore, and several other services.
Here’s a quick summary of everything we’ve discussed so far:
| Tool | Database | Search | Ingestion | Service Communication |
|---|---|---|---|---|
| Amundsen | neo4j | Elasticsearch | Databuilder | REST API |
| Apache Atlas | JanusGraph | Solr | Hooks | REST API, Kafka |
Next, let’s look at how their features differ from each other.
Data Catalog 3.0: The Modern Data Stack, Active Metadata & DataOps
Download EbookAmundsen Vs Atlas: Data catalog, lineage, and governance
Permalink to “Amundsen Vs Atlas: Data catalog, lineage, and governance”Both Amundsen and Apache Atlas support use cases for search and discovery, lineage, compliance, and quality.
Amundsen vs Apache Atlas: Key differences and USPs
Amundsen is easy to use, supports multiple backend environments, and offers a sophisticated preview feature that helps users get a better context of their data.
Apache Atlas concentrates less on integration and more on:
- Information taxonomy: Users can add business-specific contextual information using glossaries.
- Data governance: Governance teams can have greater control over the classification of database entities. Plus, glossaries and classifications can be interlinked to simplify governance.
- Integrating various metadata sources: With Hive, users can connect with any number of metadata sources without requiring custom integrations. Besides, Atlas fully supports all the Hadoop ecosystem-based data sources by default.
Before proceeding, let’s do a quick recap:
| Feature | Amundsen | Apache Atlas |
|---|---|---|
| Search and Discovery | Yes | Yes |
| OIDC / OAuth | Yes | Yes |
| Airflow Support | Yes | No |
| dbt Support | Yes | No |
| Table Lineage | Yes | Yes |
| Column Lineage | Yes | Yes |
| Classification and Tagging | Yes | Yes |
| Fine-grained access control | No | Yes |
Amundsen Vs Atlas: Deployment, authentication, and authorization
Permalink to “Amundsen Vs Atlas: Deployment, authentication, and authorization”You can build and deploy both tools using binaries and also run them on top of Docker. Here are some step-by-step setup guides to help you deploy these tools:
- Setting up Amundsen
- Setting up Apache Atlas
Amundsen Vs Atlas: Roadmap, updates, and community
Permalink to “Amundsen Vs Atlas: Roadmap, updates, and community”Amundsen has regular updates and has a large community supporting the project.
On the other hand, Apache Atlas has a public Jira project, but without a clearly defined roadmap. Apache Atlas has a blog to its name, which isn’t active. However, there are blog posts from the community that can provide insights into how data teams are using Apache Atlas and other metadata catalog tools.
Amundsen vs Apache Atlas: What’s best for you?
Permalink to “Amundsen vs Apache Atlas: What’s best for you?”Each tool has its merits. The ideal tool for you is the one that solves your business needs and gels well with your tech stack. To make things easier, we’ve summarized everything about Amundsen and Atlas with a feature matrix.
| Tool | Amundsen | Atlas |
|---|---|---|
| Developed by | Lyft | Cloudera |
| Architecture | ETL-based metadata ingestion | Hooks for metadata ingestion |
| Features | 1. Easy to set up, modify and deploy 2. Search and discovery 3. Multiple backend support 4. Data lineage (table and column) 5. Data classification and tagging |
1. Search and discovery 2. Uses JanusGraph for metadata database and Solr for search 3. Focuses on taxonomy, data governance and lineage (table and column) 4. Fine-grained access control 5. Data classification and tagging 6. Built for the Hadoop ecosystem and works with any data source using a Hive metastore |
| Deployment | 1. Kubernetes 2. AWS ECS 3. Standalone docker |
No official deployment recommendations |
| Authentication | OAuth OIDC (OpenID Connect) | 1. File 2. Kerberos SSO 3. LDAP |
| Authorization | In the roadmap | 1. Ranger-based authorization 2. Data masking |
| Roadmap and updates | 1. Amundsen roadmap 2. Updates on Medium and Stemma 3. GitHub (also lets you contribute) |
1. A public Jira project 2. Blog posts from the community on Medium |
For teams that need a managed platform rather than self-hosted open-source, Atlan provides both sides: Data Marketplace for catalog and governance that the whole organization uses, and the Context Layer that makes the same metadata graph AI-ready — built on a hardened fork of Apache Atlas, extended with 100+ cloud-native connectors.
