



















| Quick facts | Details |
|---|---|
| Type | Open-source metadata management and data governance framework |
| Maintained by | Apache Software Foundation |
| Current version | 2.4.0 (released January 2025) |
| Core model | Types (metadata definitions) and Entities (instances) |
| Backend stack | JanusGraph + HBase + Apache Solr + Apache Kafka |
| Primary ecosystem | Hadoop (Hive, HBase, Spark, Sqoop, Kafka) |
| License | Apache License 2.0 |
| Security integration | Apache Ranger (RBAC + ABAC) |
| Commercial adopters | Microsoft Purview (based on Atlas APIs), Atlan (hardened fork as metadata backend) |
Last updated: April 2026 | Version covered: Apache Atlas 2.4.0
How does Apache Atlas represent metadata?
Permalink to “How does Apache Atlas represent metadata?”Apache Atlas represents metadata as types and entities. This gives you a structured way to build, categorize, and govern data assets on Hadoop clusters. Because entities store details about metadata objects and their relationships, your metadata becomes queryable, classifiable, and traceable across the entire data ecosystem.
A Type in Atlas works like a blueprint. It defines the structure of a metadata object, similar to a class in object-oriented programming. An Entity is a specific instance of that Type. Together, they form the foundation of Atlas’s data catalog.
Labels and classifications add metadata to entities. Anyone on your team can create and assign labels. Classifications, on the other hand, are governed by system administrators through Atlas policies. According to the Apache Atlas project wiki, this model was designed to exchange metadata with tools both within and outside the Hadoop ecosystem, enabling governance controls that address compliance requirements regardless of platform.
The scale of the governance problem explains why tools like Atlas matter. The global data governance market was valued at $5.38 billion in 2025, a figure projected to reach $24.07 billion by 2034 at a 20.50% CAGR. Yet Gartner predicts 80% of governance initiatives will fail by 2027 due to a lack of a real or manufactured crisis driving prioritization.
Atlas’s influence reaches well beyond the open-source project. Microsoft Purview’s Data Catalog is based on Apache Atlas and extends full support for Atlas APIs. Atlan is built on a hardened fork of Apache Atlas as its metadata backend. Both commercial products validate the core data model while extending it for modern data stacks.
Where did Apache Atlas come from?
Permalink to “Where did Apache Atlas come from?”Apache Atlas began as the Data Governance Initiative (DGI) within Hortonworks in December 2014. Engineers from Aetna, Merck, Target, SAS, and Schlumberger needed enterprise-grade governance for Hadoop clusters. No existing tool met the requirement. The project entered the Apache Incubator in May 2015, graduated as a top-level project in June 2017, and has since reached version 2.4.0 (released January 2025).
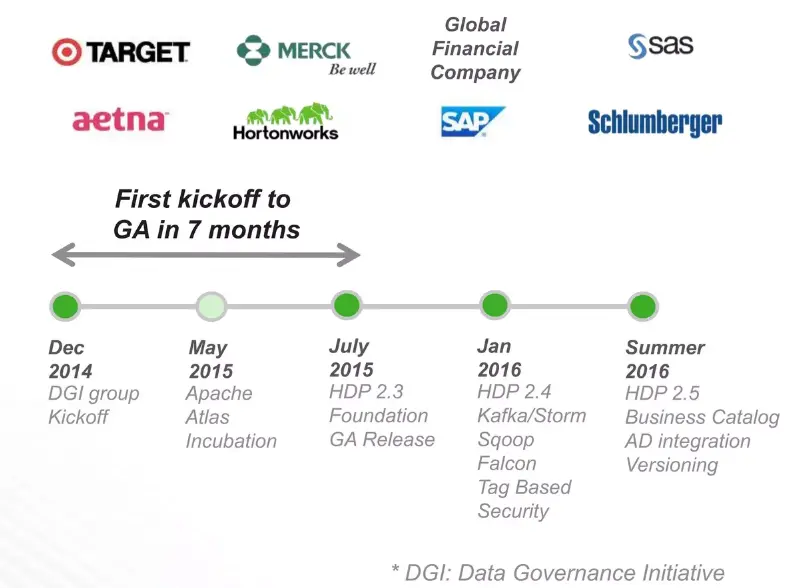
The Data Governance Initiative (DGI)
Permalink to “The Data Governance Initiative (DGI)”Hortonworks announced the DGI on January 28, 2015. The founding members pooled engineers from six organizations to build an extensible governance foundation for Hadoop.
Incubation and graduation
Permalink to “Incubation and graduation”Apache Atlas entered the Apache Incubator on May 6, 2015, and shipped its first release (0.5.0-incubating) just two months later in July 2015. The project graduated as a Top-Level Project on June 21, 2017, after two years in the incubator.
Release timeline
Permalink to “Release timeline”Atlas has gone through several major versions since graduation. The release history tells a story of expanding capabilities, a prolonged slowdown, and a recent revival.
- Version 2.0.0 (May 2019) was the first major architectural shift. It introduced soft-reference attributes, unique-attribute constraints at the graph store level, and relationship notifications. Core components jumped to Hadoop 3.1, Hive 3.1, HBase 2.0, Solr 7.5, and Kafka 2.0. (Source: Apache Atlas 2.0 Release Notes)
- Version 2.1.0 (July 2020) focused on business usability, adding business metadata attributes, labels, new models for AWS S3 and ADLS Gen2, and a beta UI.
- Version 2.2.0 (August 2021) broadened the platform’s reach with deferred actions for tag propagation, re-indexing as Java patches, support for Apache Flink and GCP models, Elasticsearch support for free-text search, and bulk glossary import with relationships. Source: Apache Atlas mailing list
- Version 2.3.0 (December 2022) delivered incremental stability fixes. Then development slowed. As the 2.4.0 release discussion notes, a two-year gap followed before the next release.
Version 2.4.0 (January 4, 2025) broke that silence with over 100 commits and meaningful improvements:
- REST APIs to receive notifications from Atlas hooks
- Dynamic index recovery improvements
- Support for aging metadata audits
- Option to download search results
- UI fixes for business glossary and search
- Replacement of log4j with logback (important security improvement)
- JanusGraph update to 1.0.0, HBase to 2.6.0, Solr to 8.11.3, Kafka to 2.8.1
Source: Apache Atlas 2.4.0 release announcement
Version 2.5.0 (in development) brings 150+ commits since 2.4.0 with several major enhancements:
- Trino metadata extractor that extends Atlas beyond Hadoop-native sources
- PostgreSQL as JanusGraph backend, dramatically reducing infrastructure footprint by removing the HBase/HDFS dependency (ATLAS-5059)
- Auto-purge feature for deleted entities
- UI migration from Backbone.js to React
- TLS 1.3 support
- Performance improvements in entity-create and edge retrieval
- Asynchronous import API
- Impala hook enhancements
The Postgres backend is the most significant architectural change in Atlas’s history. As the JIRA ticket explains, HBase and Cassandra backend stores add a significant footprint to the Atlas deployment. Replacing them with Postgres could make Atlas viable for organizations that lack a pre-existing Hadoop cluster.
The 2.4.0 release also revived the community. The March 2025 board report documented a 60% increase in mailing list traffic, 99 commits in the quarter (a 54% increase), 16 code contributors (77% increase), and a 173% increase in pull requests on GitHub.
What is Apache Atlas used for?
Permalink to “What is Apache Atlas used for?”Apache Atlas serves six core governance purposes: centralized metadata management, data lineage tracking, data classification and glossaries, automated metadata collection, classification-based security, and regulatory compliance auditing. Together, these give your team a complete picture of where data comes from, how it transforms, and who can access it.
1. Centralized metadata management and data discovery
Permalink to “1. Centralized metadata management and data discovery”Atlas provides a centralized catalog for all data assets across your organization’s ecosystem. You can use business vocabulary to search for specific assets efficiently.
This capability addresses an expensive problem. A Komprise survey (cited in the Fortune Business Insights market report) found that 68% of enterprises spend nearly 30% of their IT budget on data storage, management, and protection.
Without a centralized catalog, much of that investment goes toward data that teams cannot find or verify.
2. Data lineage tracking
Permalink to “2. Data lineage tracking”Atlas automatically generates lineage maps when it receives query information. It records the inputs and outputs of each query and builds a visualization of how data is used and transformed over time.
Lineage is supported at both table and column levels for Hadoop-native sources (Hive, Spark, Sqoop). Extending lineage to non-Hadoop sources requires custom engineering work.
3. Data classification and business glossaries
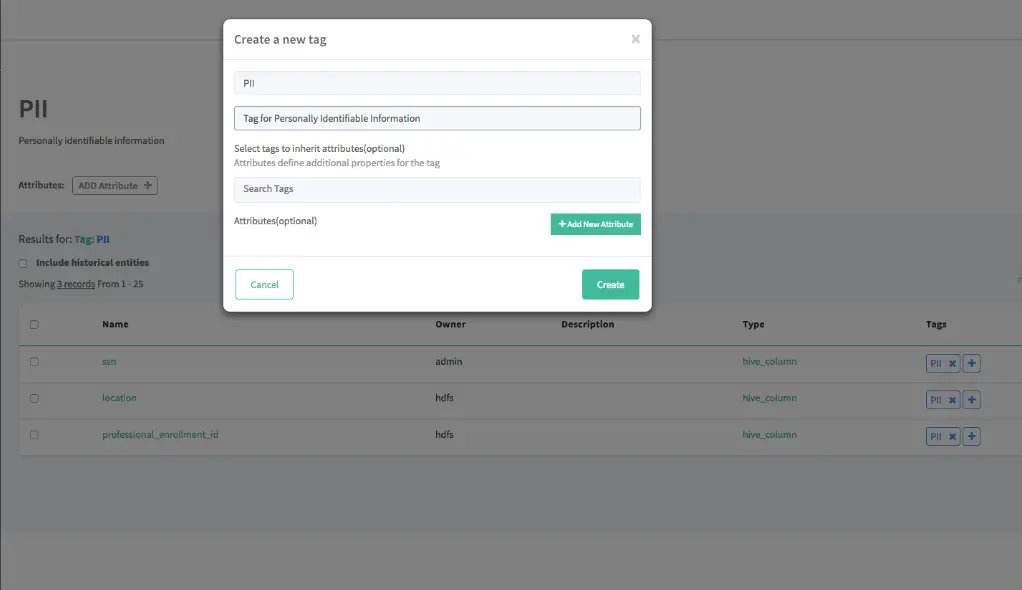
Permalink to “3. Data classification and business glossaries”Atlas provides a hierarchical classification system where classifications can be applied to entities and automatically propagated to related entities. For example, tagging a database table as containing PII (Personally Identifiable Information) can automatically propagate that classification to downstream tables and processes.
Atlas also supports a full business glossary with terms, categories, and the ability to link glossary terms to entities. The GlossaryREST API handles querying and maintaining these glossaries. When you associate a classification with a glossary term, that classification automatically propagates to all linked entities. Business teams and technical teams then work with the same definitions.
Version 2.2 enhanced bulk glossary import with support for importing terms along with their relationships.
4. Automated metadata collection via hooks and bridges
Permalink to “4. Automated metadata collection via hooks and bridges”Atlas automates metadata collection through two mechanisms:
Hooks run within external components (like Hive or Spark) and trigger on every entity operation. As described in the Atlas Architecture documentation, hooks process entities asynchronously using a thread pool to avoid adding latency to the main operation. Atlas provides pre-built hooks for Hive, HBase, Sqoop, Storm, Kafka, Impala, Spark, Couchbase, and Falcon.
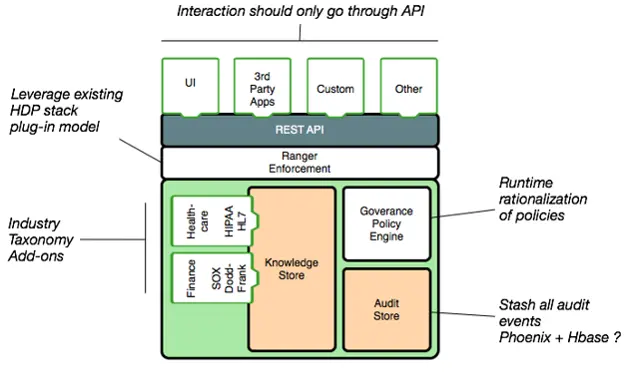
Bridges import metadata from different data assets using APIs. Import/export methods include ZIP files, REST API, and Kafka.
5. Classification-based data masking and security
Permalink to “5. Classification-based data masking and security”When integrated with Apache Ranger, Atlas enables classification-based data masking and access control. Classifications assigned to entities in Atlas can drive Ranger security policies. This lets data stewards separate data classification from access authorization. For example, any entity classified as “PII” can automatically trigger Ranger masking policies that protect sensitive fields.
Immuta’s 2024 State of Data Security Report found that 88% of data leaders expected data security to keep rising as a priority. Atlas’s classification-to-policy pipeline means a single tag does the work of configuring access rules across every asset.
6. Regulatory compliance and audit
Permalink to “6. Regulatory compliance and audit”In highly-regulated industries, Atlas provides audit capabilities that track metadata changes over time.
The v2.4.0 release added support for aging metadata audits, helping organizations manage audit data lifecycle in compliance with retention policies.
How is Apache Atlas architected?
Permalink to “How is Apache Atlas architected?”Apache Atlas is architected in three layers: metadata sources and integration (powered by Kafka), a core storage and indexing engine (JanusGraph + HBase + Solr), and applications that let teams interact with the metadata. These layers work together to ingest, store, search, and surface metadata at enterprise scale.
Source: Apache Atlas official documentation
| Layer | Component | Technology used | What it does |
|---|---|---|---|
| Metadata sources | Hooks and bridges | Hive, HBase, Kafka, Sqoop, Storm hooks | Ingest metadata from native Hadoop sources via REST or Kafka |
| Integration | Apache Kafka | Kafka topics | Route metadata messages between sources and the Atlas core |
| Core (storage) | Graph repository | JanusGraph + HBase | Store entity relationships in a column-oriented graph database |
| Core (search) | Search index | Apache Solr | Enable full-text, attribute, and DSL-based metadata search |
| Applications | Admin UI + REST API | Web UI + HTTP REST | Allow data stewards to browse, query, classify, and govern assets |
| Security | Apache Ranger | Tag-based policy engine | Enforce access control and data masking via classification tags |
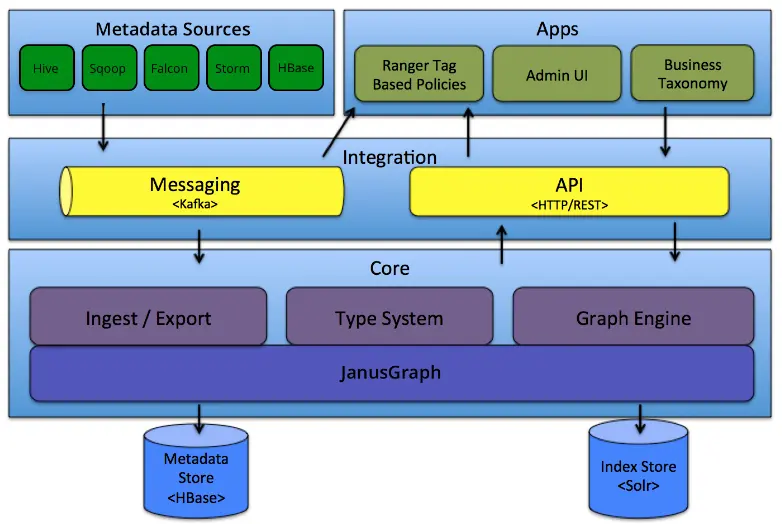
Metadata sources and integration layer
Permalink to “Metadata sources and integration layer”Atlas collects metadata through two primary integration mechanisms:
- Hooks (real-time): Pre-built hooks are available for Hive, HBase, Sqoop, Storm, Kafka, Impala, Spark, Couchbase, and Falcon. Each hook runs within the external component and asynchronously captures metadata events, publishing them to Apache Kafka topics for keeping Atlas in sync with Hadoop-native data sources in real time.
- REST API (batch/on-demand): The HTTP REST API v2 is deployed on port 21000 by default and serves as the primary method for programmatic interaction. It is divided into several endpoint groups:
- DiscoveryREST for searching entities, relationships, and classifications
- EntityREST for creating, updating, and managing entity instances
- GlossaryREST for querying and maintaining glossaries, categories, and terms
- LineageREST for capturing and retrieving lineage information
- RelationshipREST for managing relationship instances
- TypesREST for defining and retrieving type definitions
Core layer
Permalink to “Core layer”The core of Atlas has three primary components:
- JanusGraph is an open-source graph database that stores entities as vertices and their relationships as edges. This graph model allows Atlas to map complex connections between data assets and trace lineage paths. As of v2.4.0, Atlas uses JanusGraph 1.0.0.
- HBase is a column-oriented key-value database used by JanusGraph as its backend store. HBase enables Atlas to handle very large tables with sparse data resiliently. The upcoming v2.5 release introduces PostgreSQL as an alternative JanusGraph backend, which can replace the HBase + HDFS stack for organizations that don’t need extreme horizontal scalability.
- Apache Solr is an indexing engine that powers Atlas’s search capabilities using three index collections: a full-text index, an edge index, and a vertex index. These enable efficient discovery across the Atlas UI.
Notification layer
Permalink to “Notification layer”Apache Kafka sits between the metadata sources and the core, handling real-time message brokering. Hooks publish metadata events as Kafka messages, and Atlas processes them asynchronously.
This same Kafka integration enables other governance tools (like Apache Ranger) to subscribe to metadata change events for policy enforcement.
Application layer
Permalink to “Application layer”Atlas exposes a web-based admin UI for data discovery, classification management, lineage visualization, glossary curation, and governance enforcement.
The UI is currently built on Backbone.js, with a migration to React planned for v2.5.
What are the core capabilities of Apache Atlas?
Permalink to “What are the core capabilities of Apache Atlas?”Apache Atlas delivers five core capabilities that each map to a specific governance problem: a Type and Entity system for modeling metadata, graph storage for entity relationships, search for discovery, Kafka notifications for real-time integrations, and a REST API for programmatic access.
| Capability | Technology | What it enables | Governance use case |
|---|---|---|---|
| Type & entity system | Custom type definitions | Model any metadata object and its relationships | Data asset cataloging |
| Graph storage | JanusGraph + HBase | Store and query complex entity relationships at scale | Impact analysis, lineage navigation |
| Full-text search | Apache Solr | Search by type, classification, attribute, or free text | Data discovery |
| Real-time notifications | Apache Kafka | Push metadata changes and integrate with governance tools like Ranger | Access control, audit trail |
| REST API | HTTP REST (v2) | CRUD + advanced query on types, entities, lineage, and discovery | Programmatic governance integration |
1. Type system
Permalink to “1. Type system”The Type System is Atlas’s foundational module. As covered earlier, Types act as blueprints and Entities are their instances. Atlas ships with pre-defined types for Hadoop and non-Hadoop metadata, and you can define custom types to model your specific data assets.
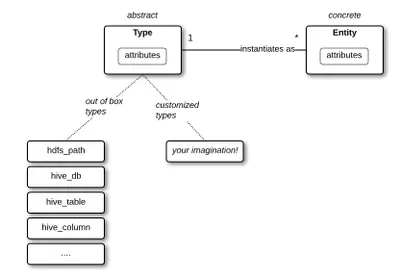
Types support primitive attributes, complex attributes, object references, and inheritance from other types.
Source: Apache Atlas official documentation
2. Graph-based metadata storage
Permalink to “2. Graph-based metadata storage”JanusGraph’s graph model enables Atlas to represent and query complex relationships among entities. Vertices represent types, and edges represent relationships.
Need to know which tables descend from a specific data source, or which processes consume a dataset? Graph traversals answer those questions faster than relational joins.
3. Full-text search via Apache Solr
Permalink to “3. Full-text search via Apache Solr”Atlas leverages Solr to provide three kinds of search: full-text search (across all text attributes), basic search (by entity type, classification, or attribute), and advanced search using Atlas’s DSL.
The v2.4.0 release included UI improvements to the search experience and updated Solr to 8.11.3.
4. Real-time notifications via Apache Kafka
Permalink to “4. Real-time notifications via Apache Kafka”Apache Kafka enables real-time ingestion of metadata and change notifications. Hooks publish metadata events as Kafka messages, and Atlas processes them asynchronously.
External tools like Apache Ranger can also subscribe to these Kafka topics, reacting to metadata changes with automated policy enforcement.
5. REST API and DSL querying
Permalink to “5. REST API and DSL querying”Beyond CRUD operations, the REST API supports advanced exploration and querying. Atlas exposes numerous REST endpoints to work with types, entities, lineage, and data discovery.
The DSL provides SQL-like query capabilities over the metadata graph for complex searches that basic search can’t handle.
6. Business glossary and ontology management
Permalink to “6. Business glossary and ontology management”Atlas’s glossary feature allows you to define business terms, organize them into categories, and associate them with technical data entities. This bridges the gap between how business teams talk about data (“customer churn rate”) and how it’s stored technically (“schema.fact_retention.monthly_exit_pct”).
Glossary terms carry classifications that automatically propagate to all linked entities. It enforces governance through business vocabulary rather than technical identifiers.
What about security and access control in Apache Atlas?
Permalink to “What about security and access control in Apache Atlas?”Apache Atlas enforces security through a classification-driven model that separates data tagging from policy enforcement. It supports RBAC, ABAC, and a pluggable authorization framework with three built-in authorizers: Simple, Ranger, and None. When integrated with Apache Ranger, tag-based policies automatically propagate access controls across Hive, HDFS, Kafka, and HBase.
RBAC and ABAC support
Permalink to “RBAC and ABAC support”According to the Apache Atlas GitHub README, Atlas supports both role-based access control (RBAC) and attribute-based access control (ABAC). Metadata integrity is maintained by leveraging Apache Ranger to prevent unauthorized access to data at runtime.
Pluggable authorization model
Permalink to “Pluggable authorization model”Atlas supports a pluggable authorization model with three built-in authorizers:
- Simple authorizer for file-based access control in basic deployments
- Ranger authorizer for policy-based authorization with full audit logging, suitable for enterprise production
- None authorizer for development and testing environments
Ranger policy model
Permalink to “Ranger policy model”When configured with the Ranger authorizer, Atlas supports three resource hierarchies for access control:
- Types: who can create/update/delete type definitions
- Entities: who can operate on specific metadata entities
- Admin operations: who can perform export/import and other administrative tasks
The Ranger authorization plugin also generates audit logs for all access decisions.
Tag-based security policies
Permalink to “Tag-based security policies”One of the most powerful security patterns involves the Atlas-Ranger integration for classification-based (tag-based) security policies. Data stewards classify assets in Atlas (e.g., “PII,” “CONFIDENTIAL”), and Ranger enforces access policies based on those classifications across Hive, HDFS, Kafka, HBase, and other components.
It separates the responsibility of classifying data from the responsibility of enforcing security. A single classification automatically triggers policies across the entire ecosystem.
How do you install Apache Atlas?
Permalink to “How do you install Apache Atlas?”Installing Apache Atlas involves five steps: setting up prerequisites (Docker, Docker Compose, Maven), cloning the repository, running Docker Compose to trigger the Maven build, loading metadata through the admin UI, and navigating entities and classifications. Budget one to three hours for a local deployment.
1. Understand the prerequisites
Permalink to “1. Understand the prerequisites”You’ll need a cloud VM or local machine running Docker and Docker Compose, access to the Apache Atlas GitHub repository, and Maven for building from source.
Atlas requires Java 8+. The embedded profile bundles HBase and Solr for evaluation purposes.
2. Clone the repository
Permalink to “2. Clone the repository”Use this command to clone the repository:
git clone https://github.com/apache/atlas.git
cd atlas
3. Build and deploy
Permalink to “3. Build and deploy”For a standalone evaluation environment using Docker Compose:
docker-compose up
This triggers a Maven build of Atlas after pulling Docker images for Hive, Hadoop, and Kafka. For building from source, the Apache Atlas GitHub README provides detailed instructions:
export MAVEN_OPTS="-Xms2g -Xmx2g"
mvn clean install
mvn clean package -Pdist
The embedded HBase and Solr profile (-Pdist,embedded-hbase-solr) is available for evaluation.
4. Load metadata
Permalink to “4. Load metadata”After logging into the Atlas admin UI (default credentials: admin/admin on port 21000), verify the server status and populate metadata using the quick_start.py script or by configuring hooks for your data sources.
5. Navigate and configure
Permalink to “5. Navigate and configure”The Atlas UI provides access to entities, classifications, glossary terms, and lineage visualization. Configure hooks for your data sources (Hive, Kafka, etc.) to enable automated metadata ingestion.
For a detailed walkthrough, check out this step-by-step Apache Atlas installation guide.
What are Apache Atlas’s limitations?
Permalink to “What are Apache Atlas’s limitations?”Apache Atlas works best for Hadoop-centric environments. Step outside that context, and you’ll run into real friction. Complex setup requirements, a Hadoop-dependent architecture, a dated UI, and slower community iteration compared to DataHub or OpenMetadata are the main concerns.
These limitations are context-dependent, not disqualifying. If you run Hadoop at scale, the tradeoffs may be acceptable. But understanding them before you commit engineering resources will save you time.
| Limitation | Impact | Who feels it most | Alternative to consider |
|---|---|---|---|
| Complex setup & maintenance | Requires Docker, Maven, HBase, Solr configuration + ongoing ops | Small teams without dedicated infrastructure | OpenMetadata (easier deployment) |
| Hadoop-centric architecture | Difficult to extend to cloud-native stacks (Snowflake, BigQuery, Databricks) without custom connectors | Cloud-first data teams | DataHub, Atlan |
| Dated UI | Search and visualization lag behind modern catalogs; learning curve for non-technical users | Data analysts, business users | Amundsen, Atlan |
| Community pace | Moderate release cadence (99 commits Q1 2025) vs. actively developed alternatives | Teams needing rapid feature evolution | OpenMetadata, DataHub |
| No managed hosting | Self-hosted only; no SaaS option | Teams without ops capacity | Atlan (managed) |
| Active-passive HA only | Only one active Atlas Web Service instance at a time; no active-active support | Orgs needing zero-downtime guarantees | Managed solutions |
| No built-in data quality | No native data quality testing or data profiling | Teams needing quality checks out of the box | OpenMetadata |
Complex initial setup
Permalink to “Complex initial setup”Atlas’s dependency stack includes HBase, HDFS, Zookeeper, Solr, and Kafka. This requires specialized knowledge to set up and operate. Reviews on TrustRadius highlight the steep learning curve and significant effort required for initial deployment.
Hadoop-centric design in a cloud-native world
Permalink to “Hadoop-centric design in a cloud-native world”Atlas’s architecture remains optimized for Hadoop environments. Organizations running Snowflake, BigQuery, or Databricks face significant custom work to connect those platforms to Atlas.
The industry shift makes this limitation sharper every year. A 2025 Iceberg ecosystem survey (published February 2026) found that only 17.9% of respondents still use Hadoop and Hive Metastore as their catalog. AWS Glue leads at 39.3%. JPMorgan Chase illustrates the shift firsthand: they migrated from Hadoop to AWS because on-premises Hadoop lacked the agility they needed for new use cases.
The upcoming Trino metadata extractor in v2.5 is a step toward broadening support. Atlas still has a long way to go to match the 84+ connectors offered by OpenMetadata or 70+ offered by DataHub.
Dated user interface
Permalink to “Dated user interface”Some reviews cite a UI that lags behind modern alternatives in usability and visual design. The v2.5 migration from Backbone.js to React should address this, but it remains a limitation in the current released versions.
Limited non-Hadoop lineage
Permalink to “Limited non-Hadoop lineage”Atlas provides strong lineage capabilities for Hadoop-native sources (Hive, Spark, Sqoop).
Extending to non-Hadoop sources like BI dashboards, cloud data warehouses, or SaaS applications requires writing custom connectors. For teams whose data ecosystem extends well beyond Hadoop, this is a critical gap.
Heavy infrastructure footprint
Permalink to “Heavy infrastructure footprint”The dependency chain (HBase, HDFS, Zookeeper, Solr, Kafka) adds up to a heavy infrastructure commitment.
This was acknowledged in the JIRA ticket introducing PostgreSQL backend support for v2.5.
Active-passive HA only
Permalink to “Active-passive HA only”The Atlas Web Service has a single-active-instance limitation.
Active-active deployments are not supported. This may be a concern for organizations requiring zero-downtime guarantees at the metadata layer.
Moderate community development pace
Permalink to “Moderate community development pace”The December 2025 board report shows roughly 41 commits per quarter and 11 code contributors. Activity spiked after the 2.4.0 release: the March 2025 board report recorded 99 commits, 16 contributors, and a 173% increase in pull requests.
The gap with newer projects is hard to ignore. DataHub has 12,500+ Slack members, 10,000+ GitHub stars, and 593 contributors. Atlas’s community is active, but operating at a different scale.
No built-in data quality
Permalink to “No built-in data quality”Unlike OpenMetadata, Atlas does not offer native quality testing or data profiling. If you need quality checks, you must integrate external tools like Great Expectations or dbt tests.
Version 2.4.0 (January 2025) addressed some resiliency issues, and v2.5 promises UI modernization and a lighter deployment footprint. If the limitations above match your experience, the alternatives and Atlan sections that follow offer paths forward.
Apache Atlas and AI/ML governance
Permalink to “Apache Atlas and AI/ML governance”Apache Atlas supports AI/ML governance as a metadata foundation for data provenance tracking, training data lineage, and RBAC/ABAC enforcement on AI workloads via Apache Ranger. It can be paired with MLflow for model experiment tracking. No native AI governance features are built in. This use case requires significant custom engineering.
AI projects fail when teams cannot trace which data trained which model. Gartner predicts that through 2026, organizations will abandon 60% of AI projects unsupported by AI-ready data. 61% of organizations are now evolving their operating models specifically because of AI technologies. Governance, not model accuracy, is becoming the bottleneck.
Apache Atlas serves as the metadata foundation in an AI governance framework. This is still an emerging use case that requires custom integration.
The most immediate application is data provenance for model training data. Atlas’s lineage capabilities can track the origin and transformation history of datasets used to train ML models. It establishes an auditable trail of what data fed into which model.
That lineage also enables fine-grained access control over AI training data. Through the Ranger integration, you can enforce RBAC/ABAC policies on data used in AI workloads, including dynamic masking of sensitive fields and encryption policies.
Beyond access control, Atlas can be paired with tools like MLflow for experiment tracking and model registry. This creates a governance bridge between data management and model management. Classifications applied in Atlas inform the downstream ML pipeline policies.
Building this takes real engineering effort. Atlas has no native AI governance features — it gives you a metadata foundation to build on, not a ready-made solution.
What are the best Apache Atlas alternatives?
Permalink to “What are the best Apache Atlas alternatives?”The most established Apache Atlas alternatives are Lyft’s Amundsen, LinkedIn’s DataHub, OpenMetadata, and Netflix’s Metacat. Each tackles gaps that Atlas leaves open in discovery, ingestion, governance, or interoperability. Your choice depends on your infrastructure, team size, and governance requirements.
Apache Atlas alternatives comparison
| Dimension | Apache Atlas | DataHub | OpenMetadata | Amundsen |
|---|---|---|---|---|
| Architecture | JanusGraph + Solr + HBase + Kafka | Kafka + Elasticsearch + JanusGraph/Neo4j | MySQL/PostgreSQL + Elasticsearch | Neo4j + Elasticsearch |
| Metadata ingestion | Hook-based (native Hadoop) | Stream-based (Kafka events) | Pull-based (Airflow) | Pull-based |
| Data quality | Not built-in | Not built-in (external) | Built-in tests + profiler | Not built-in |
| Lineage | Table + column (Hadoop-focused) | Table + column (broad, 70+ connectors) | Table + column (broad, 84+ connectors) | Limited |
| Search | Solr (DSL + basic/advanced) | Elasticsearch (advanced + semantic in v1.4) | Elasticsearch (boolean queries) | Elasticsearch |
| Non-Hadoop support | Limited (custom work needed) | 70+ native connectors | 84+ native connectors | Multiple backends |
| UI maturity | Dated (React migration in v2.5) | Modern, redesigned in v1.0+ | Modern, AI-powered in v1.12 | Modern, discovery-focused |
| Security | RBAC + ABAC via Ranger | RBAC, fine-grained access | RBAC (basic) | Limited |
| AI/ML features | None native | Agent Context Kit, MCP Server | AI Studio, AI agents, AI SDK | None |
| Best for | Hadoop-centric orgs, regulated industries | Large-scale, real-time metadata | Unified platform, smaller teams | Data discovery, quick adoption |
Sources: TheDataGuy, Bytebase, Atlan, DataHub releases, OpenMetadata GitHub
DataHub
Permalink to “DataHub”Originally developed by LinkedIn (evolving from an earlier tool called WhereHows), DataHub uses an event-driven, stream-based architecture with Kafka at its core. DataHub 1.0 was announced on January 30, 2025, marking its five-year anniversary.
As of early 2026, it has reached v1.4.0, which introduced Context Documents, a redesigned lineage navigator, AI Agent Context Kit, and connectors for additional platforms.
Best for: Large organizations needing modular, real-time metadata architecture and federated governance.
OpenMetadata
Permalink to “OpenMetadata”Built by a team inspired by Uber’s metadata infrastructure, OpenMetadata ships a unified platform covering discovery, governance, quality, profiling, lineage, and collaboration. It deliberately avoids using a graph database, instead relying on MySQL/PostgreSQL and Elasticsearch for a simpler architecture. OpenMetadata is the only major open-source catalog with built-in data quality testing and data profiling.
The latest release (v1.12, February 2026) introduced AI Studio with customizable AI agents, a Metadata AI SDK, custom AI-powered classification recognizers, comprehensive audit logs, and aggregate column management.
Best for: Teams wanting a broad, unified feature set without managing complex infrastructure.
Amundsen
Permalink to “Amundsen”Created by Lyft, Amundsen uses a microservices architecture with Neo4j for graph-based relationship modeling and Elasticsearch for search. It focuses on data discovery and ease of use rather than comprehensive governance. According to TheDataGuy’s framework comparison, Amundsen provides sophisticated data previews for better contextualization.
Best for: Organizations prioritizing data discovery and quick user adoption over governance enforcement.
Marquez
Permalink to “Marquez”Marquez is the reference implementation of the OpenLineage standard. It works out of the box with every OpenLineage integration: Apache Airflow, Apache Spark, Apache Flink, dbt, and Dagster. Marquez focuses purely on lineage tracking rather than discovery or governance.
Best for: Teams that need lineage-first metadata tracking and are already using OpenLineage-compatible tools.
Netflix’s Metacat
Permalink to “Netflix’s Metacat”Metacat ensures interoperability and data discovery at Netflix via change notifications, defined metadata storage, and unified aggregation of data from diverse sources. It is more niche than the alternatives above and is primarily designed for Netflix’s internal federated data ecosystem.
How does Atlan help where Apache Atlas falls short?
Permalink to “How does Atlan help where Apache Atlas falls short?”Atlan’s metadata backend is a hardened fork of Apache Atlas — the same graph model, extended for enterprise-scale operations and connected to 100+ cloud-native sources including Snowflake, Databricks, BigQuery, dbt, and Airflow. Where Atlas requires teams to self-host JanusGraph, HBase, Solr, and Kafka, Atlan provides managed infrastructure with built-in high availability, automated upgrades, and zero Hadoop dependency.
For human teams, Atlan’s Data Marketplace delivers conversational data discovery, automated governance workflows (PII detection, GDPR tagging, access policy enforcement), and data products with quality scores and ownership signals. First-time users navigate without training. Virgin Media O2 onboarded 6,000 people in a single year. CME Group cataloged 18M+ assets with 1,300+ glossary terms in year one.
For AI agents, the same metadata graph feeds Atlan’s Context Layer. Context Agents automatically generate descriptions, metrics, business terms, and semantic relationships from the data graph — enrichment at a scale that manual documentation cannot match. AI agents query the resulting context via MCP, SQL, and API before acting on enterprise data. The difference: 94–99% AI accuracy with proper context grounding, compared to 10–31% without (published research).
Atlan is a Leader in the Gartner Magic Quadrant for Metadata Management (2025, 2026), a Leader in the Forrester Wave for Data Catalogs (2025), and rated #1 in Data Catalog and Data Governance on G2. Gartner awarded Atlan the highest score for data lineage and impact analysis in their Critical Capabilities report.
Here is how Atlan addresses the specific gaps in Apache Atlas:
- Managed deployment: No self-hosted ops burden. Atlan handles infrastructure, scaling, and maintenance so your team can focus on governance, not operations.
- Cross-cloud connectors: Native integrations with Snowflake, BigQuery, Databricks, and dozens of other modern data platforms address Atlas’s Hadoop-centric limitation.
- Automated PII/GDPR tagging: Playbooks automate classification workflows that Atlas requires you to manage manually.
- Context Agents: Atlan’s Context Agents automatically enrich metadata — generating descriptions, metrics, business terms, and semantic relationships from the data graph at machine speed. 90%+ acceptance rate across 350K+ AI descriptions.
These capabilities translate into real outcomes:
From Weeks to Hours: How Tide Automated GDPR Compliance
"We needed to tag personally identifiable information across our entire data estate to strengthen GDPR compliance for 500,000 customers. Manual processes would have taken 50 days. Using automated rule-based workflows, we completed the tagging in just five hours."
Data Governance Team
Tide
🎧 Listen to the podcast: How Tide Automated GDPR Compliance
From Hours to Minutes: How Aliaxis Reduced Effort on Root Cause Analysis by almost 95%
"A data product owner told me it used to take at least an hour to find the source of a column or a problem, then find a fix for it, each time there was a change. With Atlan, it's a matter of minutes. They can go there and quickly get a report."
Data Governance Team
Aliaxis
🎧 Listen to the podcast: Aliaxis's Global Data Journey with Atlan
If you’re evaluating open-source Atlas versus a managed solution, consider the total cost of ownership. The software is free. The engineering hours for setup, custom integration, ongoing maintenance, and operational support are not.
FAQs about Apache Atlas
Permalink to “FAQs about Apache Atlas”What is Apache Atlas, and how does it help with data governance?
Permalink to “What is Apache Atlas, and how does it help with data governance?”Apache Atlas is an open-source metadata management and data governance framework. It provides capabilities for building data catalogs, tracking data lineage, enforcing classification-based policies, and maintaining business glossaries. It helps organizations consistently apply governance policies across their data ecosystem, with particular strength in Hadoop environments and regulated industries.
How can I use Apache Atlas to track data lineage across my systems?
Permalink to “How can I use Apache Atlas to track data lineage across my systems?”Atlas reads metadata from hooks and bridges, notes the inputs and outputs of data operations, and automatically generates lineage maps. These maps trace how data is used and transformed over time. Lineage is stored in JanusGraph and can be queried through the LineageREST API or visualized in the Atlas UI. Table and column-level lineage is supported for Hadoop-native sources, with custom work needed for non-Hadoop platforms.
What are the benefits of using Apache Atlas in a cloud-based architecture?
Permalink to “What are the benefits of using Apache Atlas in a cloud-based architecture?”Atlas provides a centralized metadata layer that can span on-premises and cloud environments. Through its REST API, you can ingest metadata from cloud-native tools. The upcoming v2.5 release adds PostgreSQL as a backend option, reducing reliance on Hadoop infrastructure. That said, Atlas’s strongest integrations remain Hadoop-native, and cloud-first teams may find modern alternatives like DataHub or OpenMetadata easier to adopt.
How does Apache Atlas integrate with other data management tools?
Permalink to “How does Apache Atlas integrate with other data management tools?”Atlas integrates through two primary mechanisms. Hooks run within external components like Hive, Spark, and Kafka to capture metadata in real time. The REST API v2 enables programmatic metadata ingestion from any system. Atlas also integrates with Apache Ranger for classification-based security policies and supports Kafka-based event subscriptions, enabling external tools to react to metadata changes.
How does Apache Atlas ensure compliance and security in my enterprise?
Permalink to “How does Apache Atlas ensure compliance and security in my enterprise?”Atlas supports both RBAC and ABAC through its integration with Apache Ranger. Classifications applied to entities can drive Ranger security policies for data masking, row-level filtering, and access control across Hadoop components. The Ranger plugin also generates audit logs for compliance reporting. The v2.4.0 release added support for aging metadata audits.
What features make Apache Atlas an open-source solution for metadata governance?
Permalink to “What features make Apache Atlas an open-source solution for metadata governance?”Atlas provides a Type and Entity system for flexible metadata modeling, JanusGraph for graph-based relationship storage, Apache Solr for full-text search, Kafka for real-time notifications, and a REST API for programmatic access. It also offers a business glossary, hierarchical classification with automatic propagation, and deep integration with Apache Ranger for security. All of these are available under the Apache License 2.0.
What are the main limitations of Apache Atlas?
Permalink to “What are the main limitations of Apache Atlas?”Apache Atlas’s main limitations are its Hadoop-centric architecture, complex setup requirements (Docker, Maven, HBase, Solr), and dated UI. It’s also self-hosted, with no managed SaaS option. Teams running modern cloud-native stacks on Snowflake or BigQuery will find integration challenging without custom connectors. Version 2.4.0 addressed some resiliency issues, but the core limitations remain.
How does Apache Atlas compare to DataHub?
Permalink to “How does Apache Atlas compare to DataHub?”Apache Atlas focuses on governance depth through classification hierarchies, policy enforcement, and lineage for Hadoop-native tools. DataHub, developed by LinkedIn, focuses on contextual understanding and real-time metadata ingestion across a broader set of modern sources. Atlas is better for Hadoop governance. DataHub is better for teams needing flexible ingestion and a modern stack.
Is Apache Atlas still actively maintained?
Permalink to “Is Apache Atlas still actively maintained?”Yes. Apache Atlas is actively maintained by the community under the Apache Software Foundation. Version 2.4.0, released January 2025, brought over 100 commits, including security improvements, UI fixes, and component upgrades. The development mailing list saw strong engagement in 2025, with a 173% increase in pull requests. That said, release cadence is moderate compared to newer alternatives like OpenMetadata or DataHub.
Is Apache Atlas the right choice for your stack?
Permalink to “Is Apache Atlas the right choice for your stack?”For teams running Hadoop at scale with strong engineering capacity, Atlas remains a capable governance framework. Its Ranger-based security integration provides classification-driven access control that few open-source alternatives match.
The tradeoffs are real, though. The dependency stack is heavy, the UI needs modernization, and non-Hadoop integration requires custom engineering. As discussed in the limitations section, the industry is moving toward cloud-native catalogs, and Hadoop adoption continues to shrink. Atlas’s relevance as a standalone deployment is narrowing, even as its architectural patterns persist in commercial products.
If open-source Atlas fits your stack, build on it. If the engineering overhead of self-hosting is the barrier, managed platforms like Atlan offer Atlas’s governance model with 100+ cloud-native connectors, automated governance workflows, and the Context Layer that serves metadata to both human teams and AI agents — without requiring a dedicated infrastructure team.
