



















Amundsen and OpenMetadata are two popular open-source metadata catalogs in the market. Both these tools share many features, but there are certain vital differences too.
Here we will compare both these tools based on their architecture, ingestion methods, capabilities, available integrations, and more. Before that, let’s take a quick preview of both.
Is Open Source really free? Estimate the cost of deploying an open-source data catalog 👉 Download Free Calculator
What is OpenMetadata?
Permalink to “What is OpenMetadata?”OpenMetadata was announced and open-sourced in late 2021 and was built by some of the same engineers who created Uber’s Databook metadata management platform. OpenMetadata was designed to simplify working with metadata and implement various open standards in the tool. OpenMetadata’s fresh approach has attracted many users, along with over a hundred contributors so far.
Read more about OpenMetadata here.
An overview of OpenMetadata
What is Amundsen?
Permalink to “What is Amundsen?”Amundsen was created at Lyft to solve problems around data discovery and metadata management. Lyft announced and open-sourced the Amundsen project in 2019. Since then, many companies, big and small, such as Square, Instacart, Delivery Hero, Coles, Asana, and more, have implemented Amundsen to handle all of their metadata. Over two hundred people have contributed to the open-source project to support active development and community building.
Read more about Amundsen here.
An overview of Amundsen Data Catalog
OpenMetadata vs Amundsen: Factors for comparison
Permalink to “OpenMetadata vs Amundsen: Factors for comparison”Let’s compare Amundsen and OpenMetadata on multiple fronts, including:
- Architecture and technology stack
- Search and discovery
- Data lineage and data quality
- Data governance and data security
- Integrations
We’ve narrowed down the above criteria to draw a comparison between these tools with an understanding of what’s critical to know. Especially if you are evaluating one of them as a metadata management platform for your organization.
Let’s consider each of these factors in detail and clarify our understanding of how they fare.
OpenMetadata vs. Amundsen: Architecture and technology stack
Permalink to “OpenMetadata vs. Amundsen: Architecture and technology stack”OpenMetadata uses a pull-based metadata extraction mechanism, which it processes and pushes to DropWizard (OpenMetadata’s HTTP server). The initial extraction and processing are facilitated by jobs orchestrated in Apache Airflow. Once the data is pushed to DropWizard, it is written to two different data stores - MySQL and Elasticsearch.
MySQL stores the metadata entities and their relationships, while Elasticsearch enables full-text search capabilities by allowing inverted indexes on metadata entities. OpenMetadata does not use a separate graph database to store entity relationships.

From fragmented, duplicated, and inconsistent metadata to a unified metadata system. Source: OpenMetadata
On the other hand, Amundsen has its data ingestion library, which you can use with Apache Airflow or a similar tool. From the ingestion framework, the data lands in Elasticsearch to support the full-text search capabilities and neo4j to support the storage and access of entities and their relationships.
All of this is exposed via a Flask-based web application. On top of that, Amundsen also allows you to use other graph-oriented databases, such as AWS Neptune, in place of neo4j.
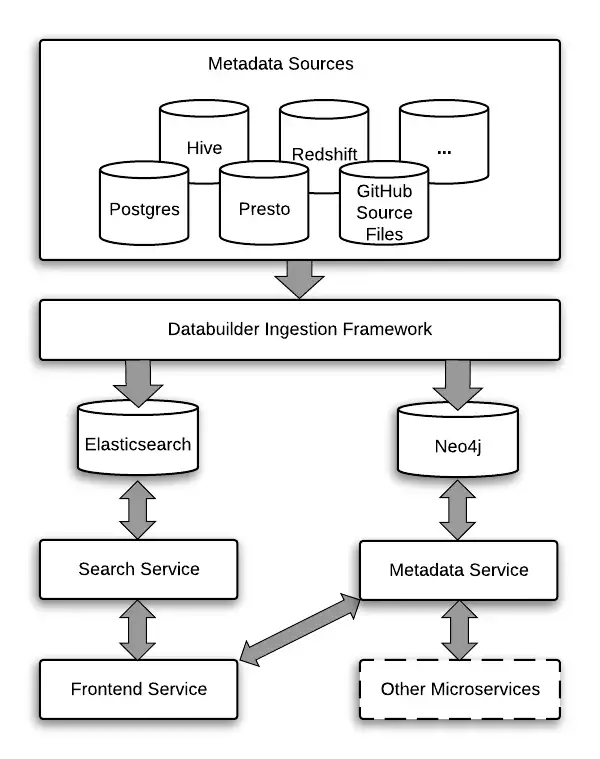
Microservices architecture of Amundsen. Source: Lyft Engineering
OpenMetadata vs. Amundsen: Search and discovery
Permalink to “OpenMetadata vs. Amundsen: Search and discovery”As mentioned in the previous section, Amundsen and OpenMetadata use Elasticsearch to enable the full-text search capability. Still, in both tools, the search capability is augmented by various additional data points about the collected metadata. We’ll talk more about this in one of the later sections on data governance.
With a powerful search engine, discovering data assets becomes easy, significantly because OpenMetadata also empowers the search experience by providing profiling data for various data assets. OpenMetadata’s search service enables you to search based on keywords, data lineage, entity relationships, and complex boolean queries across all data assets.
OpenMetadata also allows you to add custom metadata to any data assets, such as descriptions and tags. The custom metadata is also indexed in Elasticsearch to enable search operations.
Since its release, Amundsen hadn’t looked at the search functionality at all. Still, owing to constant feedback from Lyft’s own internal users, Amundsen moved to upgrade Elasticsearch to v7 to use some of the advanced features, make changes to the backend, and work on features like multi-value filtering, negation filtering, filtering autocomplete, and better ranking and relevance.
This resulted in the search functionality being revamped in late 2021.
OpenMetadata vs. Amundsen: Data lineage and data quality
Permalink to “OpenMetadata vs. Amundsen: Data lineage and data quality”Amundsen’s data lineage got quite a bit of an upgrade when they started offering native support for table and column-level lineage metadata ingestion directly into the neo4j graph database.
OpenMetadata allows you to fetch lineage metadata from multiple sources. In addition to basic data lineage features, OpenMetadata also lets you manually edit data lineage.
Amundsen and OpenMetadata support tools like Airflow and dbt for pushing lineage data into the tool. We’ve previously written a detailed tutorial if you want to set up data lineage using dbt in Amundsen.
OpenMetadata also offers a Lineage Workflow connector for lineage ingestion. This connector can currently support lineage data from data sources, such as Snowflake, Redshift, PostgreSQL, BigQuery, Databricks, and a few others.
Regarding data quality, OpenMetadata focuses on allowing users to ensure that the data assets are trustable. OpenMetadata enables data quality through out-of-the-box support for creating custom tests and integrating tools like Great Expectations.
On the other hand, Amundsen allows you to integrate data profiling and quality tools using the Table API so that you can import reports generated by those tools and show them in the Amundsen UI.
OpenMetadata vs. Amundsen: Data governance and data security
Permalink to “OpenMetadata vs. Amundsen: Data governance and data security”Both OpenMetadata and Amundsen support basic data governance features, such as RBAC (role-based access control), tags, and business glossary. Amundsen’s architectural approach is to strike a balance between security and data democratization, where the team members are free to discover and use the data. Still, they should have the authorization and authentication mechanism to do that.
OpenMetadata has made data governance one of the core features on offer. In addition to security features like audit-enabling change activity feed, OpenMetadata allows you to perform soft deletes in the UI to ensure that essential data about data assets or access to data assets is never lost for compliance, auditing, and other business-specific reasons.
On top of those features, OpenMetadata also allows you to annotate data assets using tags, set an importance parameter on the data assets, and add ownership information to every data asset in the system. This, combined with the RBAC system, makes OpenMetadata’s data governance promising.
OpenMetadata vs. Amundsen: Integrations
Permalink to “OpenMetadata vs. Amundsen: Integrations”Amundsen supports a range of data sources for metadata extraction. You can connect to these sources using table connectors.
You can also use dashboard connectors to connect to reporting and business intelligence tools, such as Apache Superset, Redash, Tableau, and so on. Finally, you can also use Apache Airflow for custom ETL workflows.
OpenMetadata is also big on integrations. Like Amundsen, OpenMetadata also allows you to integrate with databases, data warehouses, and business intelligence tools.
However, OpenMetadata takes it a step forward with the support for integration with messaging services, such as Kafka and Pulsar, multiple orchestration services, such as Airflow, AWS Glue, Dagster, Airbyte, etc., and ML model services, such as Mlflow.
In addition, OpenMetadata also allows you to integrate with other metadata services, such as Amundsen and Apache Atlas.
Comparison summary
Permalink to “Comparison summary”Although both Amundsen and OpenMetadata have quite a few differences in the internal architecture and priorities, still there’s enough overlap for a fair comparison. Given that the two tools were created almost two years apart, one has the advantage of learning from the other. With that, let’s look at some of the features of both tools side-by-side:
| Feature | OpenMetadata | Amundsen |
|---|---|---|
| Search & discovery | Elasticsearch | Elasticsearch |
| Metadata backend | MySQL | Neo4j |
| Metadata extraction | Push | Push-and-pull |
| Metadata ingestion | Push-and-pull | Pull |
| Data governance | RBAC, glossary, tags, importance, owners, and the capability to extend entity metadata | RBAC, tags, business glossary |
| Data lineage | Column-level | Column-level |
| Data profiling | Built-in with the possibility of using external tools | In the roadmap |
| Data quality | Built-in with the possibility of using external tools like Great Expectations | In the roadmap; some integrations possible |
Additional resources
Permalink to “Additional resources”OpenMetadata
Permalink to “OpenMetadata”Slack | GitHub | Documentation | Sandbox | Medium | Roadmap | Swagger
Amundsen
Permalink to “Amundsen”Slack | GitHub | Twitter | Medium | Community Meetings
