


















Atlan vs DataHub
Choose the Metadata Platform That Operationalizes Context Across the Enterprise
Trusted by companies
with more than $10T in enterprise value

Affirm chose Atlan as a partner to power an extensible governance platform
"We looked for a partner whose vision, development, and engineering culture matched ours. We are an API-first company and needed APIs to extend the catalog into a platform that could integrate across systems."

Ankit Singh
Tech Leadership

"Being a fintech company, we wanted to focus on what matters for our customers — not maintaining infrastructure and becoming an infrastructure company. For us, that's undifferentiated work."
Ankit Singh
Tech Leadership
"People behind the solution matters. We looked at their ability to solve problems when things got difficult. This gives us confidence we have a partnership, not just buying the current software & tomorrow roadmap"
Ankit Singh
Tech Leadership
Atlan vs DataHub:
Key differences that deliver better outcomes
| What Teams Need | DataHub | |
|---|---|---|
| Metadata lakehouse (core differentiator) | Iceberg-Native Lakehouse - Separated storage/compute. Optimized for multi-cloud/AI workloads | OSS Platform - Built on GraphQL/OpenLineage. Scale and infra are self-managed |
| App framework (core differentiator) | App Exchange - Developer first tools for AI apps/connectors. 20+ external partners already building | No Native Framework - Relies on OSS scripts. Extensions require manual engg/PRs |
| MetaModel | Flexible, No-Code - UI-interface for admins to define custom metadata attributes | Structured, Schema-First - Requires developers to define new "Aspects" using PDL files |
| Event driven architecture | CDC and webhooks with Kafka for dynamic metadata capture | Runs on a Kafka-based Metadata Change Log (MCL) |
| What Teams Need | DataHub | |
|---|---|---|
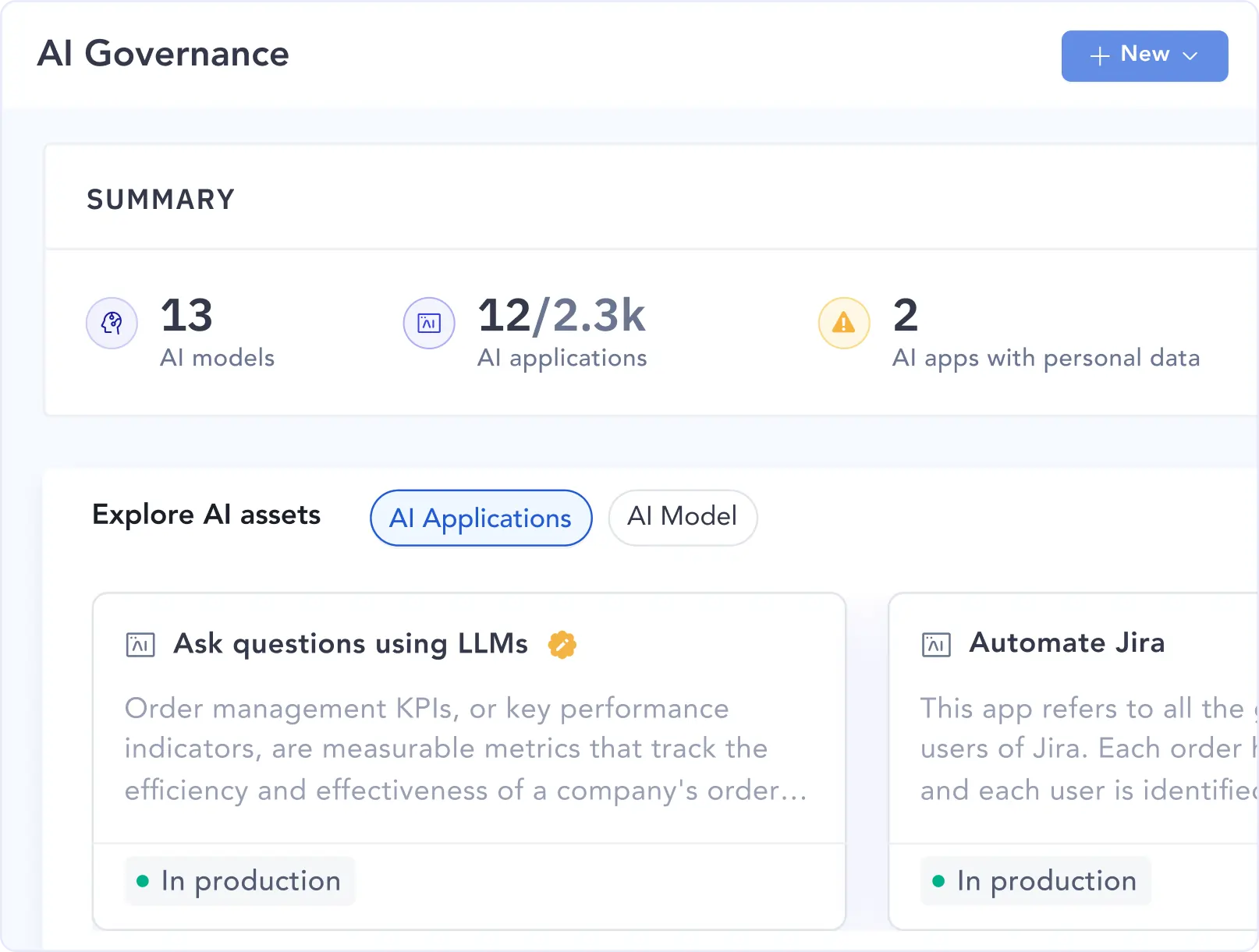
| AI governance (core differentiator) | Unified governance for data and AI assets, including model lineage, explainability, and compliance | No AI governance or model lineage capabilities |
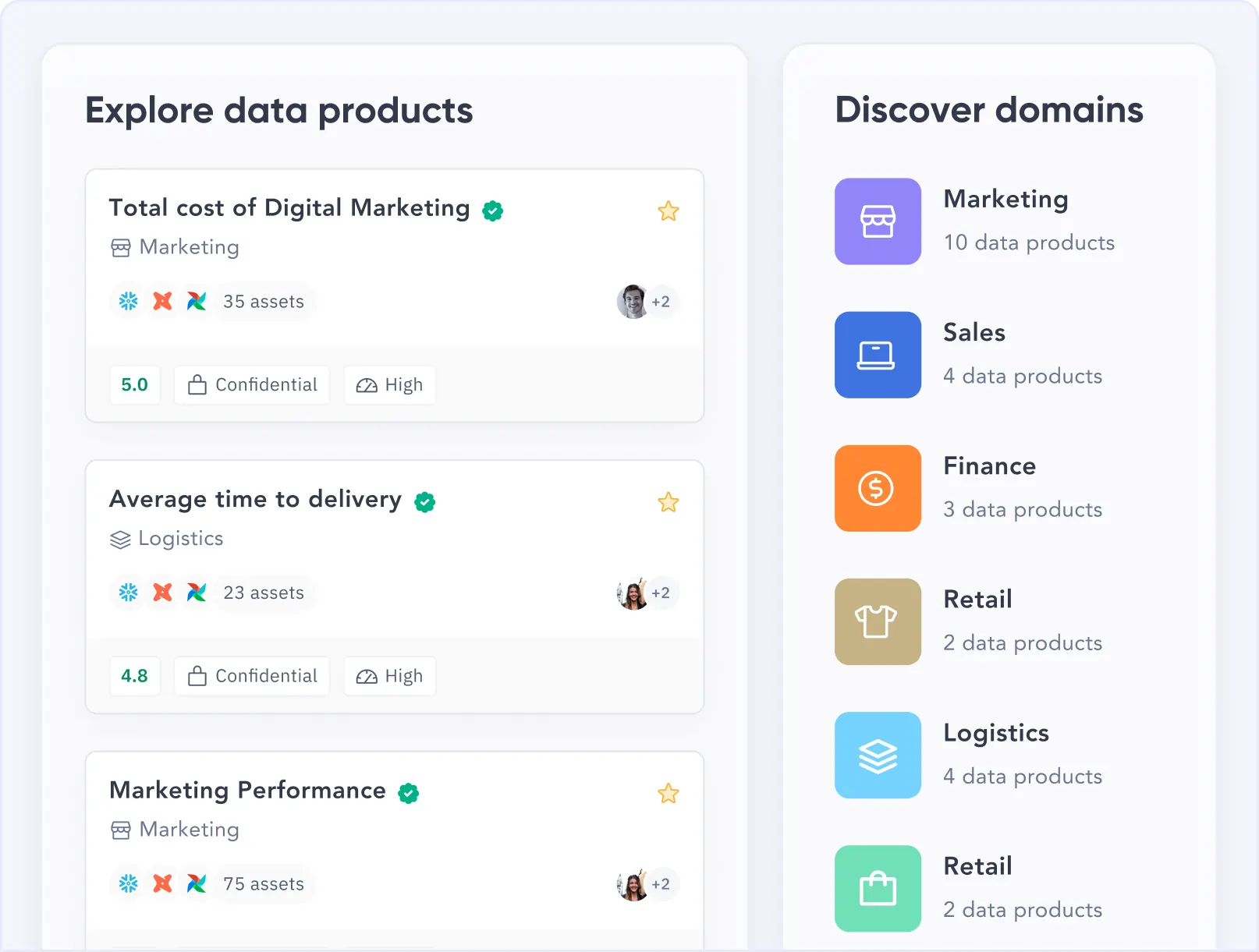
| Data product marketplace (core differentiator) | Curated data product marketplace with usage scoring, access controls | Basic "data product" tagging. Lacks marketplace and scoring |
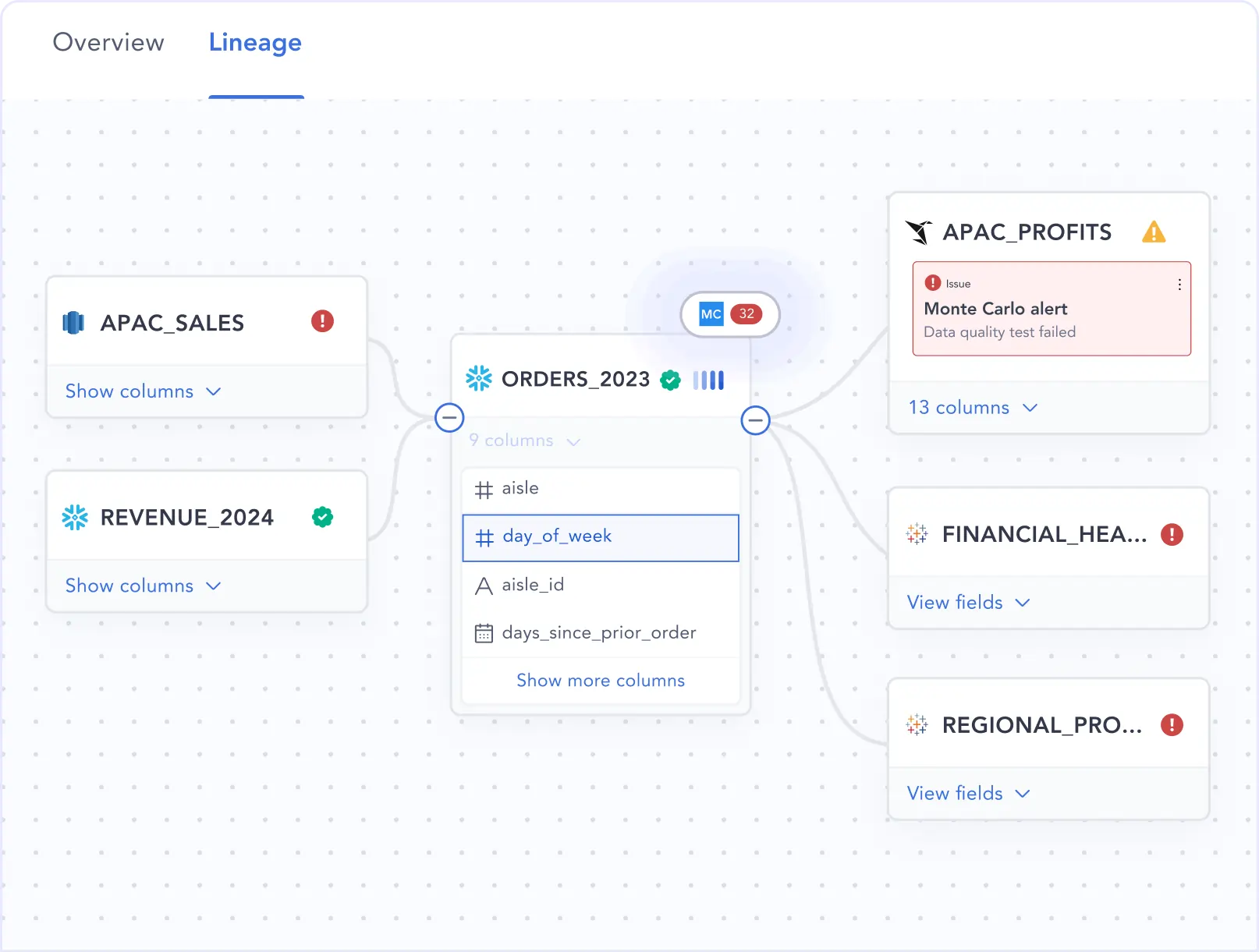
| Lineage & impact analysis | Column-level lineage for 30+ sources with proactive impact analysis (Github CI/CD) | Column-level lineage for 20+ sources with simple impact analysis |
| Workflows and Policy Manager (core differentiator) | Native Policy Manager (cross-system) & Advanced DIY Governance Workflow Builder | Limited policies (Datahub-only, not data sources). Basic governance workflows |
| Tag management | 2-Way Tag Sync. Bulk tagging via playbook. Upstream & Downstream lineage propagation | 1-Way Tag Sync. Bulk tagging via metadata tests. Downstream only lineage propagation |
| What Teams Need | DataHub | |
|---|---|---|
| Personas served | Supports All Personas - Data Governance, Data Producers and Data Consumers | Supports primarily technical personas |
| Collaboration | Chrome extension for major BI tools. Integration with Slack, MS Teams, ServiceNow, JIRA, MS excel and Google Sheets | Basic Chrome extension & integration with Slack |
| UI/UX | Modern, intuitive, personalised for all personas for enterprise adoption | User-friendly experience for technical users, not non-technical |
| What Teams Need | DataHub | |
|---|---|---|
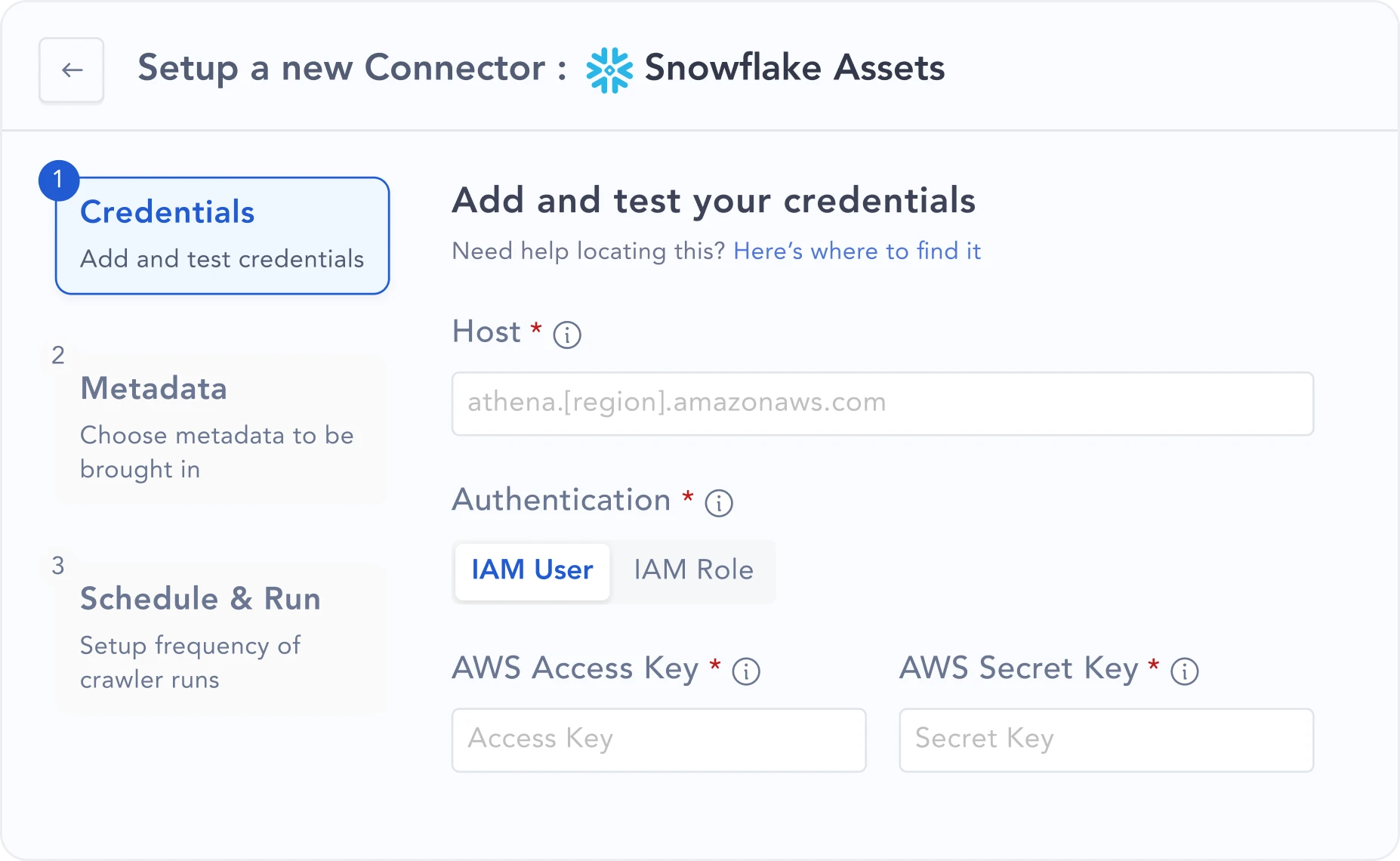
| System coverage | 100+ Native/API-First Connectors. Breadth across modern/legacy (e.g.SAP ECC) & depth in MDS (e.g. Snowflake) | ~60 OSS connectors. Community maintained |
| Post-Sales & Support Model | Partnership-Focused - Dedicated CSM, 24/7 SLAs, & CX adoption services | Focus on Stability/Expert Help. Provides tiered technical SLAs |
| Pricing model | Starts at $100K/year. Aligned with asset volume and users. | Varies by setup. Total cost includes infra and DevOps |

Why data and AI-forward enterprises choose Atlan over DataHub
Data leaders chose Atlan for tangible business outcomes and superior product fit.
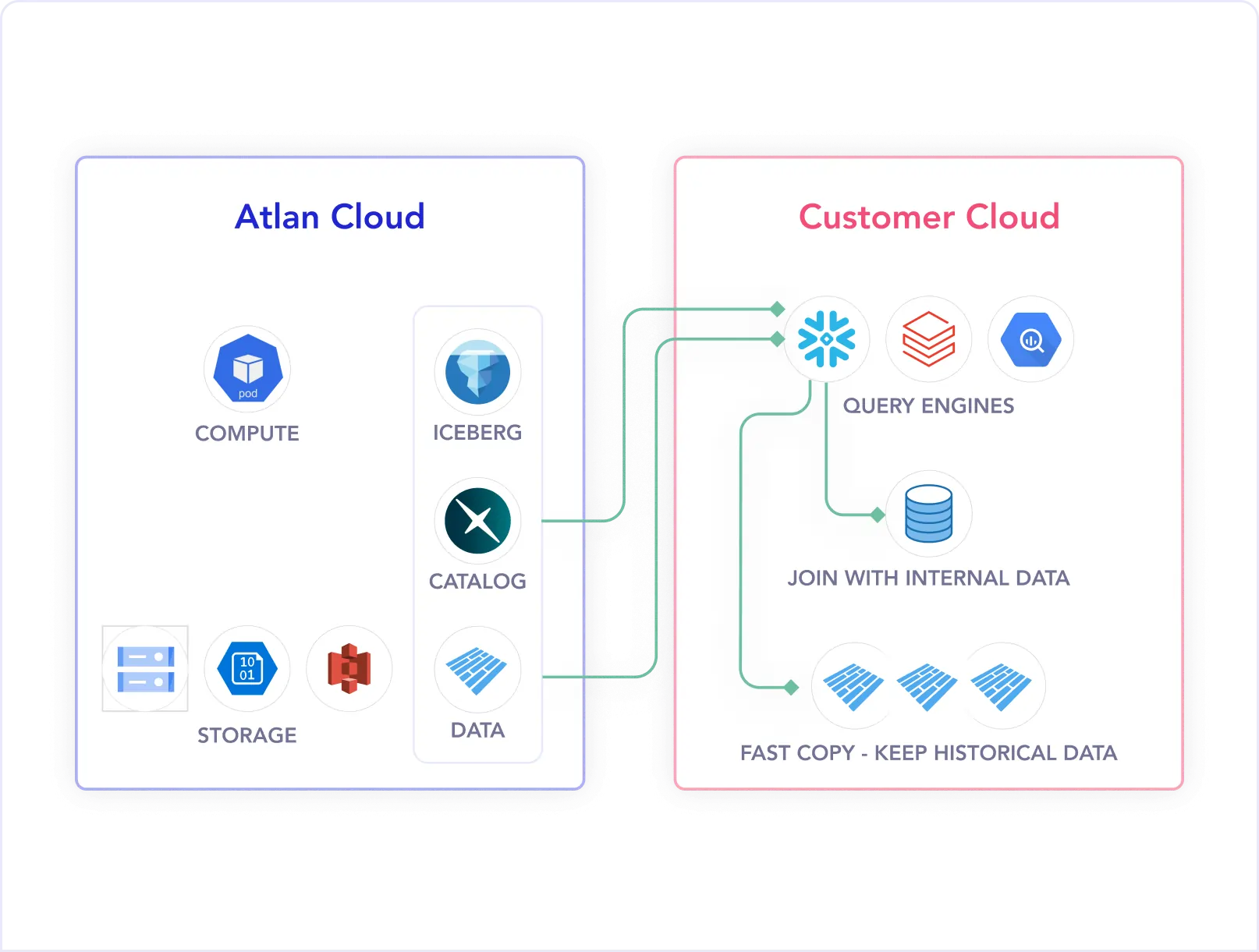
Build or buy? With Atlan, you don't have to choose.
Open-source tools like DataHub offer flexibility but require heavy engineering resources to secure, maintain, and scale.
Managed platforms provide reliability but limit customization and control.
Atlan brings the best of both worlds
- The hybrid advantage: Atlan's platform is open by design - with robust APIs/ developer SDK, iceberg-native metadata lakehouse and developer first app exchange for easy extensibility.
- Focus on outcomes: Atlan manages the burden of infrastructure, upgrades, and uptime. This frees your team to concentrate on more data projects and AI innovation.
- Proven at scale: Atlan is trusted by enterprises with more than $10 trillion in value, with the likes of Affirm, GM, and Mastercard, proves that openness and enterprise scale can coexist.
- Industry recognition: Validated by leading analysts and partners including Forrester, Gartner, and Snowflake for innovation and customer impact.
Frequently asked questions: Atlan vs DataHub
Does Atlan support Bring Your Own Cloud (BYOC) or on-prem deployments?
DataHub requires teams to host and maintain their own infrastructure or rely on managed OSS offerings, which increases operational overhead.
How does Atlan's Metadata Lakehouse differ from DataHub's backend architecture?
DataHub operates as an OSS metadata platform built on open standards like GraphQL and OpenLineage; scale and extensions are self-managed rather than lakehouse-based.
Can Atlan integrate directly with Databricks, Snowflake, and dbt?
How extensible is Atlan's API and SDK framework?
Does Atlan provide developer tooling similar to OSS frameworks?
How does Atlan handle automation and lineage at scale?
How is Atlan optimized for AI and LLM use cases?
Can Atlan manage unstructured data or logs?
How does Atlan support metadata versioning and change tracking?
What kind of scalability can Atlan handle?
Does Atlan offer support for multi-tenant or domain-first data architectures?
Is Atlan secure enough for regulated industries?
DataHub's OSS model requires manual setup for comparable controls.