



















OpenMetadata explained
Permalink to “OpenMetadata explained”OpenMetadata is an open-source metadata store that can help you enable data cataloging, discovery, and collaboration across your data ecosystem. OpenMetadata was launched in the latter half of 2021. It has had twelve minor releases, with the latest one being 0.12.0; a major release is yet to take place.
Watch Context Studio Demo
OpenMetadata was inspired by the learnings accumulated while building Uber’s metadata infrastructure, which can be thought of as the first iteration of OpenMetadata. Uber’s metadata system features in-house tools like Databook.
In their announcement blog, Suresh Srinivas, founder of OpenMetadata cited reasons why Uber’s in-house system wasn’t open-sourced itself, rather Open Metadata was built ground up. The reasons fundamentally stem from the idea to ensure that the priorities of the company and the open-source community are not in conflict in the process of evolution of such a tool.
OpenMetadata is one of the latest additions to the open-source data cataloging landscape that includes other tools like Amundsen, DataHub, Apache Atlas, and so on.
Here, we will take you through the basics of OpenMetadata in terms of the following key themes:
- Design principles and architecture choices
- Features
- Integrations supported
In the end, we’ll also supply you with further reading materials, links, and resources. Let’s dive right in.
Design principles and architecture choices that define OpenMetadata
Permalink to “Design principles and architecture choices that define OpenMetadata”In this section, we’ll take a look at the following principles that guided OpenMetadata’s design and architecture:
- Unified metadata model
- Open and standardized APIs for integrations
- Metadata extensibility
- Pull-based metadata ingestion
- Graph storage for metadata
Unified metadata model: what it means in practice
Permalink to “Unified metadata model: what it means in practice”Businesses work with a range of data sources to serve different purposes. These data sources have their architectures aligned to specific use cases; some are document-oriented, some store geolocation data, and so on. Because these data sources differ in how they store data, it is natural for them to store the underlying metadata also differently.
To enable organization-wide data discovery, data governance, and data lineage features, you need to have a unified metadata model. This will enable you to configure and maintain different integrations in a centralized fashion. With a unified metadata model, it will also be easy to expose metadata for the consumption of internal microservices and external applications. Here’s a diagram from OpenMetadata’s blog that depicts such as setup.

From fragmented, duplicated, and inconsistent metadata to a unified metadata system. Source: OpenMetadata
Open and standardized APIs for integrations
Permalink to “Open and standardized APIs for integrations”The unified metadata model helps OpenMetadata to enable better integration with diverse data sources. That added with open APIs based on well-documented and widely-accepted schema standards helps OpenMetadata to expose the unified data model for various downstream applications, such as a data catalog, data quality engine, and so on.
You can get the Open API specification for the REST API that exposes all the metadata extracted and enriched in OpenMetadata from the Swagger specification document.
The Open APIs are backed by the same strongly-type, well-structured, and annotated schema following the JSON Schema specification. OpenMetadata also uses the same specification for defining data quality tests.
Metadata extensibility
Permalink to “Metadata extensibility”If there’s one thing you can be sure of in any business is that organization, processes, and priorities always change. To cater to custom requirements, the metadata model needs to be flexible enough to handle any additional data points, nodes, and other fields.
This means that the unified metadata model can be conceptually split into two parts - the base metadata model and the extended metadata model.
The base metadata model consists of all the metadata that is common across multiple data sources and the extended metadata model will take care of any data source-specific customizations. OpenMetadata, much like DataHub and many others, has been designed to be extensible.
Pull-based metadata ingestion: what it means in practice
Permalink to “Pull-based metadata ingestion: what it means in practice”Most metadata ingestion systems are pull-based, which means that the metadata extraction is the responsibility of the metadata engine, and not the data source. Some metadata catalogs, such as DataHub support both push and pull-based metadata ingestion.
OpenMetadata has taken the pull-based approach as the authors of OpenMetadata believe, “no metadata system can be purely push-based”.
The thinking behind this choice is that data sources can’t be reasonably expected to push data into a metadata aggregation system. The job of extracting and transforming metadata into a unified metadata model falls on the data cataloging tool, much like what an ETL tool does for creating data lakes and data warehouses.
Graph storage for metadata
Permalink to “Graph storage for metadata”OpenMetadata takes the approach of storing metadata in a centralized fashion where it is “actively organized as a graph connecting data” with all teams, tools, and processes.
This enables organizations to build, maintain, and utilize a “Metadata Graph” that can be consumed by downstream applications to enable many value-adding features, such as data cataloging, data governance, data lineage, automated data quality, and testing, data profiling, data observability, and so on.
Applications of OpenMetadata
Permalink to “Applications of OpenMetadata”OpenMetadata is built to support the following applications:
- Data discovery
- Data governance
- Data lineage
- Data quality
- Integrations
- Metadata versioning
Data discovery
Permalink to “Data discovery”OpenMetadata’s data discovery features are powered by a full-text search engine that can search through not just the entity definitions, but also their descriptions, extended metadata, conversation threads, tasks, and announcements. When you are on the OpenMetadata console, you can initiate a search by using the CMD + K shortcut, as shown in the image below:

Snapshot of search functionality in OpenMetadata. Source: OpenMetadata
To complement the search engine functionality, OpenMetadata offers an easy way to navigate both the technical and business metadata for your data sources. The technical metadata is captured from the data sources as is and is enriched by features like conversation threads, tasks, and announcements, as mentioned earlier.
Data governance
Permalink to “Data governance”Backed by the unified metadata model, OpenMetadata has implemented the following three features to enable data governance across your organization:
- Role-based access control (RBAC)
- Ownership
- Importance
A sophisticated role-based access control system with an organization-wide team hierarchy and a role-policy-rule-based access control sets a solid foundation for data governance in OpenMetadata.
Building an ownership and importance layer on top of the RBAC enhances the value OpenMetadata brings to a business. Let’s take a glimpse of OpenMetadata’s RBAC engine in action.
The following image shows the page on the UI where you can create and manage roles:
")
OpenMetadata supports role-based access controls (RBAC). Source: OpenMetadata
And this image shows the page on the UI where you can create and manage different policies.
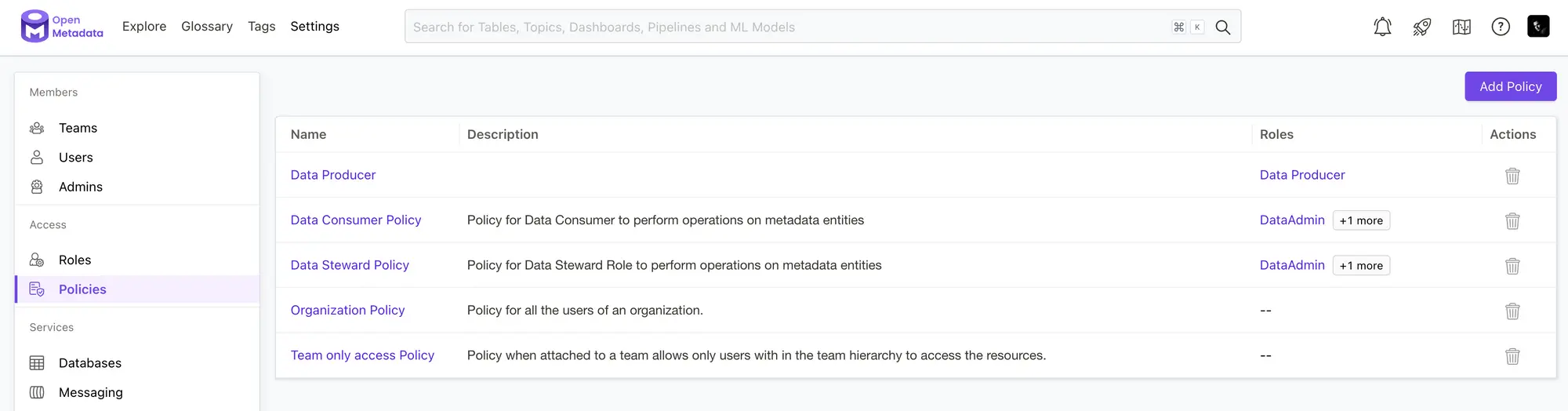
Policies attached to roles help control access to metadata operations. Source: OpenMetadata
Data lineage
Permalink to “Data lineage”OpenMetadata primarily capitalizes on its query parser to collect lineage data, however, it also uses dbt and data source query logs to build and enrich data lineage.
OpenMetadata manages data lineage in the following ways:
- Automated collection of data lineage
- Manual addition of data lineage
- Editing existing data lineage
OpenMetadata captures lineage in an automated manner, triggered by tools like Airflow, Prefect, etc.
It also allows you to add lineage manually because there might be cases where the data sources might not provide reliable information about the lineage.
And finally, OpenMetadata takes it one step forward by allowing you to edit data lineage if the data lineage visualization doesn’t reflect the actual lineage between different data assets.
Here’s a quick peek into how data lineage is visualized in OpenMetadata:

View upstream and downstream dependencies for data assets with lineage. Source: OpenMetadata
Data quality
Permalink to “Data quality”Tackling data quality across data sources is one of the most challenging tasks in the data engineering domain today, but again, because of OpenMetadata’s unified data model, it is easy to define tests and run profiles on data assets across different data sources.
OpenMetadata allows you to group different tests together and create a test suite, as shown in the image below:

Run tests to monitor data reliability. Source: OpenMetadata
You can run a test suite on the data assets you want. The following image shows you the output for the test runs for one of the sample data assets:

Run quality tests on specific data assets. Source: OpenMetadata
OpenMetadata has tightly integrated data quality in the UI to enable data teams to make it a part of their usual workflow. This way data quality issues are always visible to the team consuming the data, which makes fixing these issues faster and easier.
Metadata versioning
Permalink to “Metadata versioning”Similar to how you capture changes in data using CDC tools, OpenMetadata enables you to capture changes in the structure of data assets along with any related metadata with the help of metadata versioning. OpenMetadata’s metadata versioning follows a major.minor versioning pattern with any minor release being backward compatible and any major release being backward incompatible.

Version history helps track changes in data assets. Source: OpenMetadata
Metadata versioning is instrumental in providing valuable information to developers and data users when they’re collaborating across teams with different data sources and also when they are trying to debug an issue with the data. This enables transparency in the handling of data across the organization which results in a better overall collaboration between teams while keeping the metadata clean and up-to-date.
Integrations supported by OpenMetadata
Permalink to “Integrations supported by OpenMetadata”Most data cataloging tools now enable data extraction using a Singer-like, connector-based model.
OpenMetadata currently offers more than fifty connectors for metadata ingestion from data sources like databases, data lakes, data warehouses, business intelligence tools, message queues, data pipelines, and even other data catalogs.
As OpenMetadata is open-source, you may see more connectors being written by members of the community as and when required. OpenMetadata also integrates with Great Expectations for data quality workloads and Prefect for data workflows.
OpenMetadata Resources
Permalink to “OpenMetadata Resources”Although it has only been just over a year since OpenMetadata’s launch, there’s been quite a bit of development. Here’s a curated list of resources that might help you navigate your OpenMetadata learning journey and keep up to speed with further developments.
- GitHub Repo
- Slack Community
- Google Group
- Demo
- Technology Blog
- Roadmap
- Community Discussions
- Swagger API Specification
Conclusion
Permalink to “Conclusion”Here, we took you through the basic design, architecture, and prominent features of OpenMetadata.
The resources we’ve shared above should be able to steer you in the right direction if you’re thinking about evaluating OpenMetadata as a metadata management platform for your stack.
When evaluating OpenMetadata, take your time to review your data cataloging, governance, and lineage requirements and OpenMetadata’s features in those areas, and see if there’s enough alignment for you to go through a POC.
Also, as with any other open-source project, assess it on specific general criteria, like popularity, maturity, activity, release cycles, and the roadmap. A combined view of all these things will help you decide which of the data cataloging and governance tools makes the most sense for your business.
If you are a data consumer or producer and are looking to champion your organization to optimally utilize the value of a modern data stack, it’s worth taking a look at off-the-shelf alternatives like Atlan — Atlan is built on open source, and open by default.
Atlan empowers organizations to establish and scale data governance programs by automating metadata management, providing end-to-end lineage tracking, enabling collaboration across diverse personas, and offering an extensible platform for customized governance workflows and integrations.
Atlan’s approach ensures data quality, security, and compliance while fostering data literacy and self-service across the organization.
Tide’s Story of GDPR Compliance: Embedding Privacy into Automated Processes
Permalink to “Tide’s Story of GDPR Compliance: Embedding Privacy into Automated Processes”- Tide, a UK-based digital bank with nearly 500,000 small business customers, sought to improve their compliance with GDPR’s Right to Erasure, commonly known as the “Right to be forgotten”.
- After adopting Atlan as their metadata platform, Tide’s data and legal teams collaborated to define personally identifiable information in order to propagate those definitions and tags across their data estate.
- Tide used Atlan Playbooks (rule-based bulk automations) to automatically identify, tag, and secure personal data, turning a 50-day manual process into mere hours of work.
Book your personalized demo today to find out how Atlan can help your organization in establishing and scaling data governance programs.
A demo of Atlan for data discovery
FAQs on OpenMetadata
Permalink to “FAQs on OpenMetadata”What is OpenMetadata?
Permalink to “What is OpenMetadata?”OpenMetadata is an open-source metadata management platform that supports data cataloging, discovery, and collaboration. It enables organizations to maintain a unified metadata system, fostering data governance and quality.
What are the main principles behind OpenMetadata’s design?
Permalink to “What are the main principles behind OpenMetadata’s design?”OpenMetadata is built on key principles such as a unified metadata model, open APIs for integration, metadata extensibility, pull-based metadata ingestion, and graph storage.
How does OpenMetadata handle metadata ingestion?
Permalink to “How does OpenMetadata handle metadata ingestion?”OpenMetadata uses a pull-based metadata ingestion method, meaning the metadata engine retrieves data from sources rather than relying on those sources to push data, which ensures consistency and reliability.
What makes OpenMetadata’s integration unique?
Permalink to “What makes OpenMetadata’s integration unique?”It offers open and standardized APIs that follow widely accepted schema standards, allowing seamless integration with downstream applications like data catalogs and quality engines.
Why does OpenMetadata use graph storage for metadata?
Permalink to “Why does OpenMetadata use graph storage for metadata?”Graph storage in OpenMetadata enables the organization to build a metadata graph, connecting data with processes, tools, and teams, which supports features like data lineage, governance, and observability.
